Similarity-Driven Research
— Andrew Janco

- Thoughtful process
- Dedicated team
- Pixel-perfect work
- 24/7 support
- Think about comparison as a humanities research practice
- How language models create embeddings that enable comparison
- Evaluate what "semantic similarity" means in this context
- Identify productive directions for similarity-driven computational research methods.
"...comparison is one of the most basic scholarly operations--a functional primitive of humanities research..."
-- John Unsworth, 2000

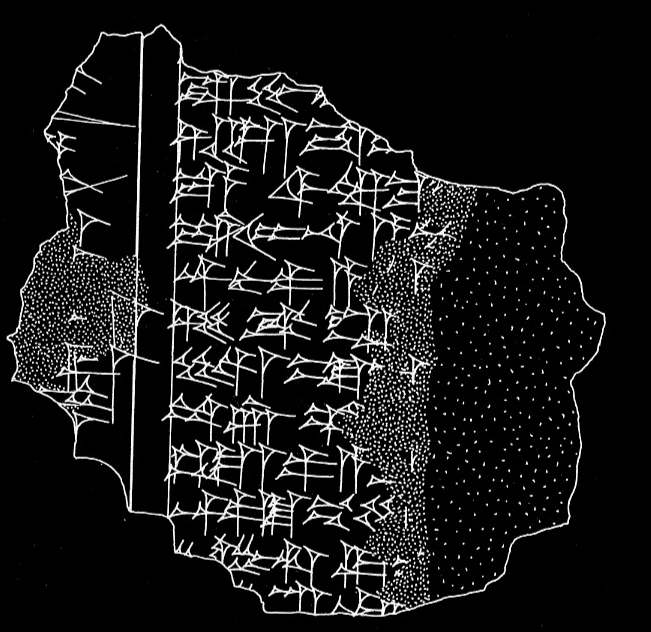
Two fragments with "Story of the Flood (Atraḫasīs)" electronic Bablyonian Library
〞
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity
– Conrad Anker
--Wikipedia
Embedding
A learned numerical representation of text, image or other media
Encoder
Decoder
"reset"
«перезагрузить»[0.222233,0.334322,0.2313545,0.222322,2.33224422,8.332352424,7.974....]
Nomic Embed
Open Code
The architecture and code used to train the model is published and available: https://github.com/nomic-ai/contrastors
2.
Open Weights
The trained model is available to download and run on your own computer.
3.
Learning: Collocation & Classification
Contrastive Representation Learning
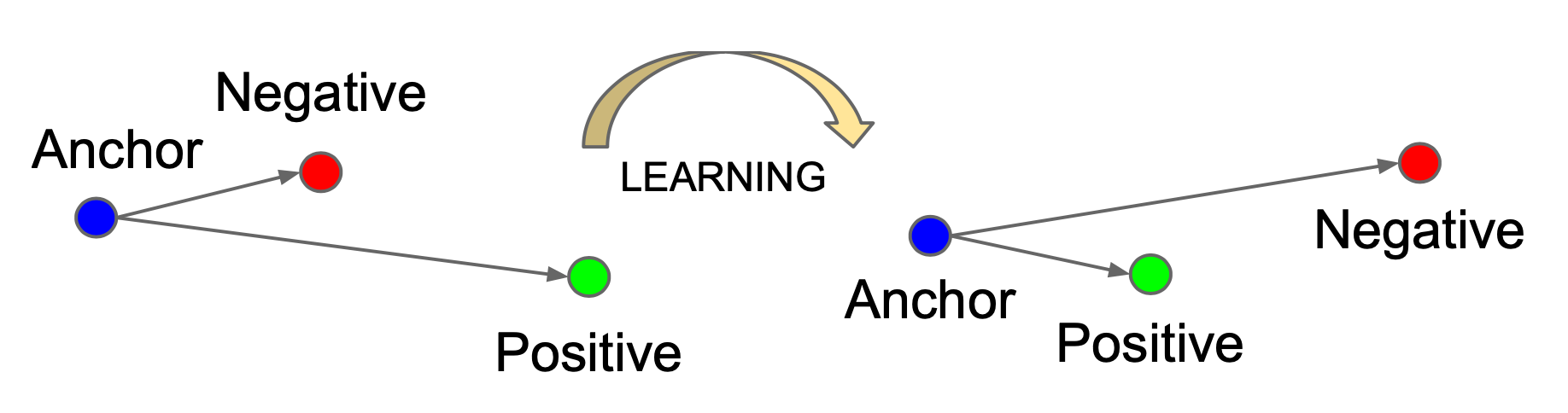
A method to learn embeddings where similar pairs of texts are moved nearer to one another and relatively far from dissimilar (negative) texts
Triplet loss
A number is calculated that rewards the model when the anchor is nearer to the positive and farther from the negative. During training, the model works to reduce this error and to generate embeddings where paired texts are near to one another in vector space.
Training Data for Nomic Embed
query_text: Seeking Energy Independence, Europe Faces Heated Fracking Debate
document_text: While watching the turmoil in Ukraine unfold, you may feel as though it has little to do with the United States, but the conflict is stirring a contentious debate in Europe over a topic familiar to many Americans: fracking...
paired_text: Seeking Energy Independence, Europe Faces Heated Fracking Debate While watching the turmoil in Ukraine unfold, you may feel as though it has little to do with the United States, but the conflict is stirring a contentious debate in Europe over a topic familiar to many Americans: fracking....
∼235M text pairs
task-specific for question/answer, classification and clustering

What do computers really mean by "semantic text similarity?"
Types of Similarity
lexical
semantic
orthographic
stylistic
thematic

words or vocabulary
spelling and writing
themes or concepts
common style or authorship
meaning or semantic content

https://bit.ly/prozhito-map

"Scalable Information Cartography"
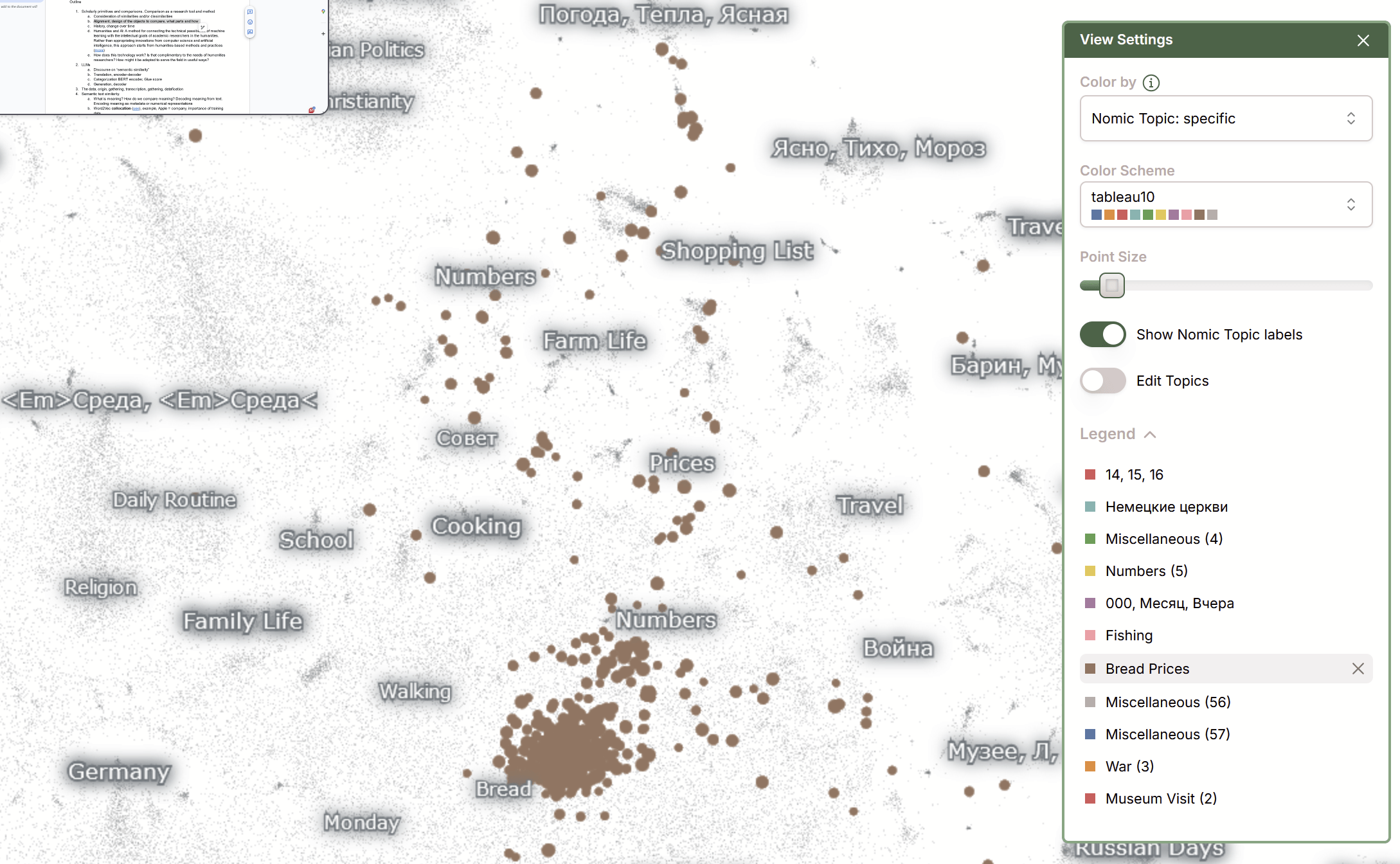
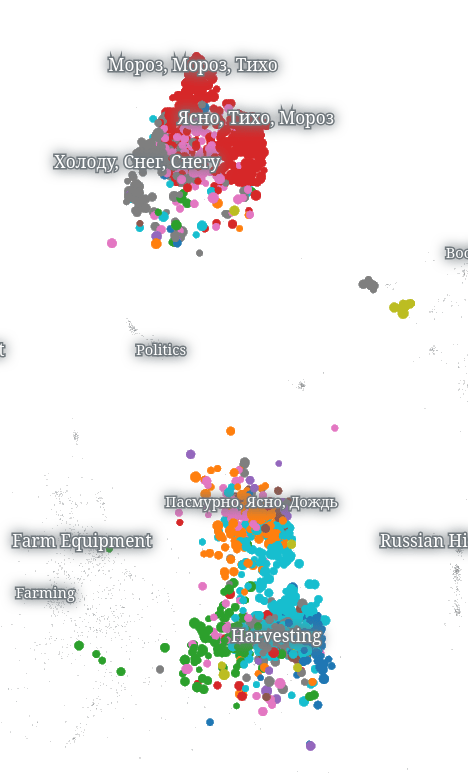
Bread Prices
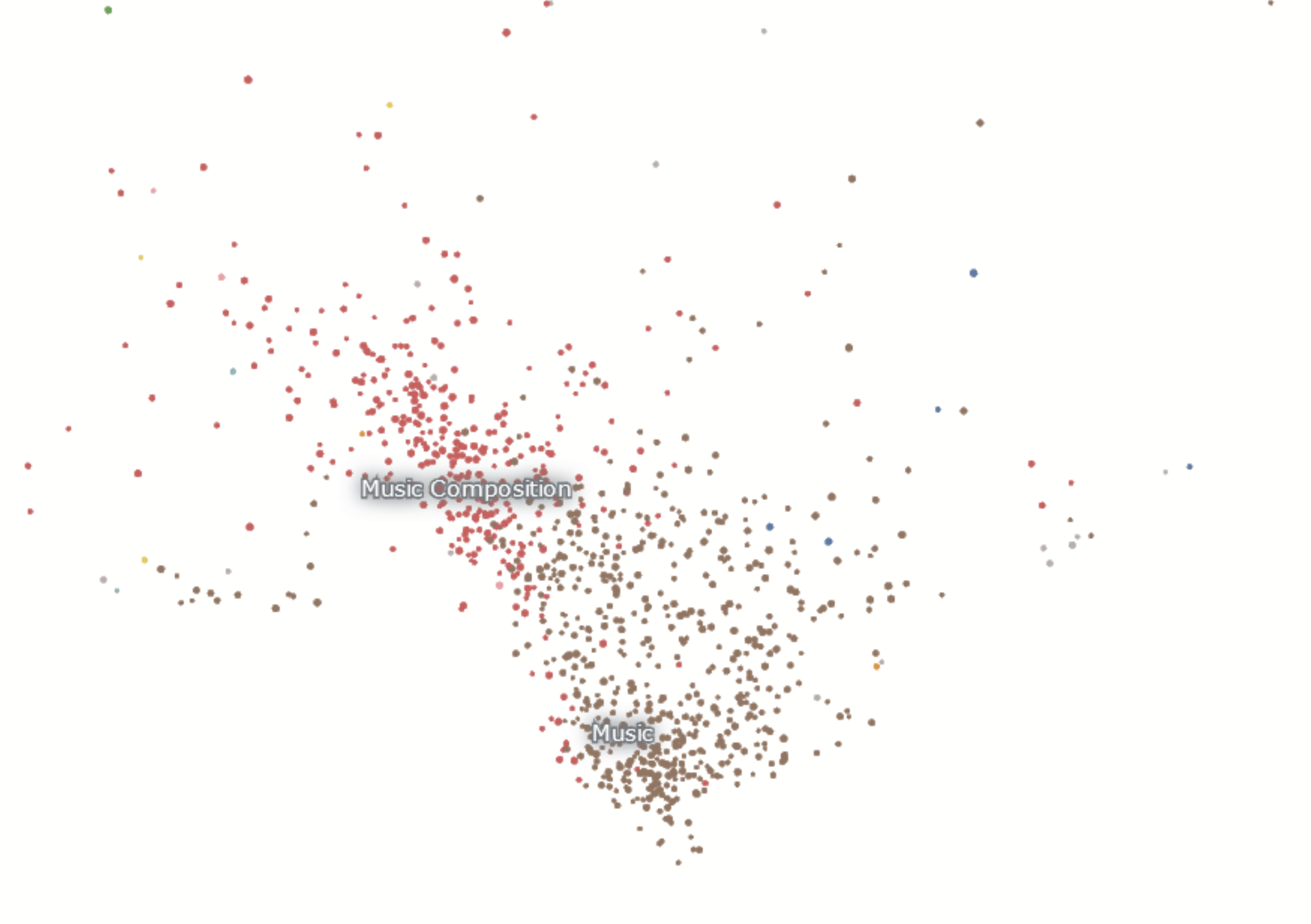
Music
topical
^Пятница\W
lexical
^Понедельник\W
lexical
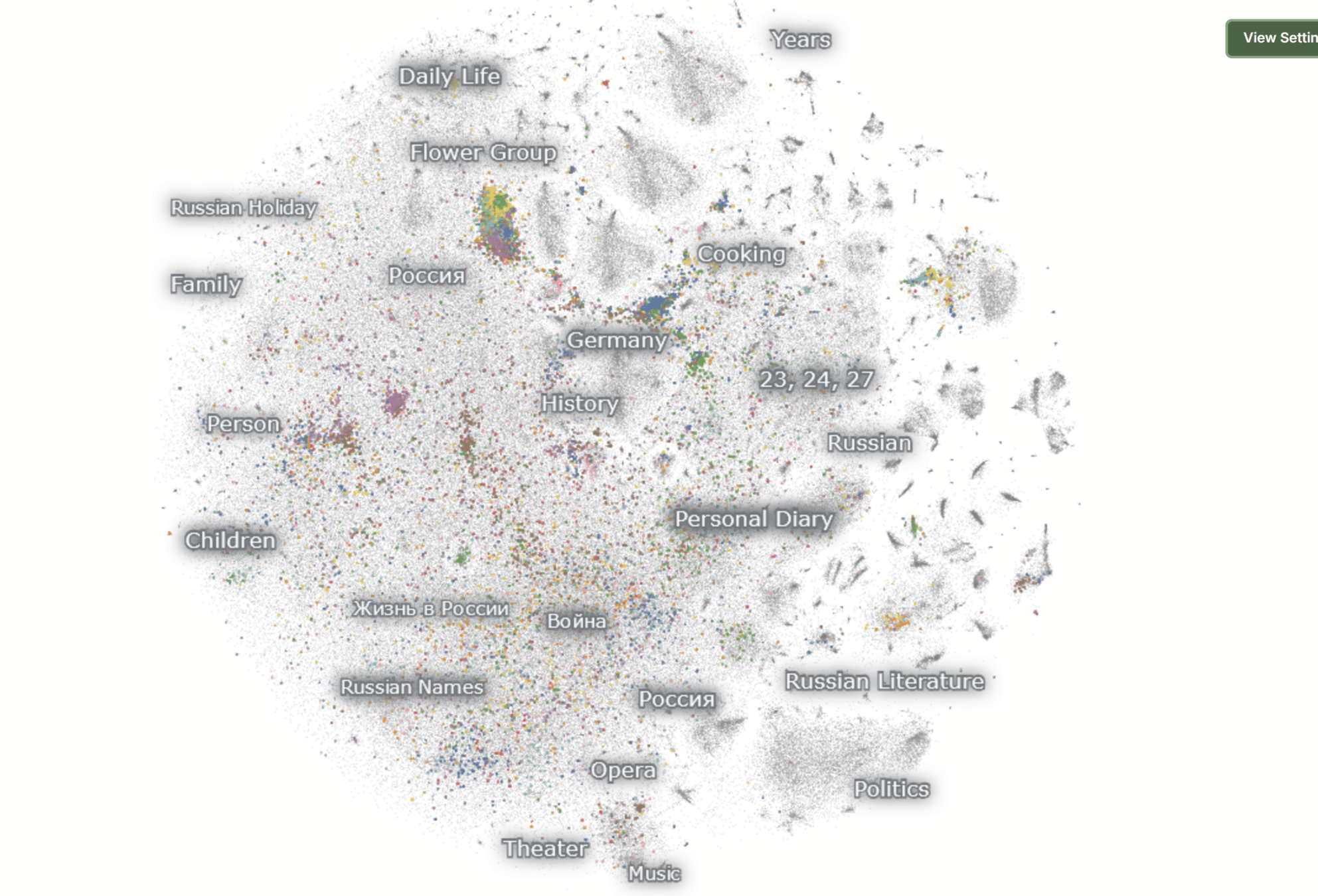

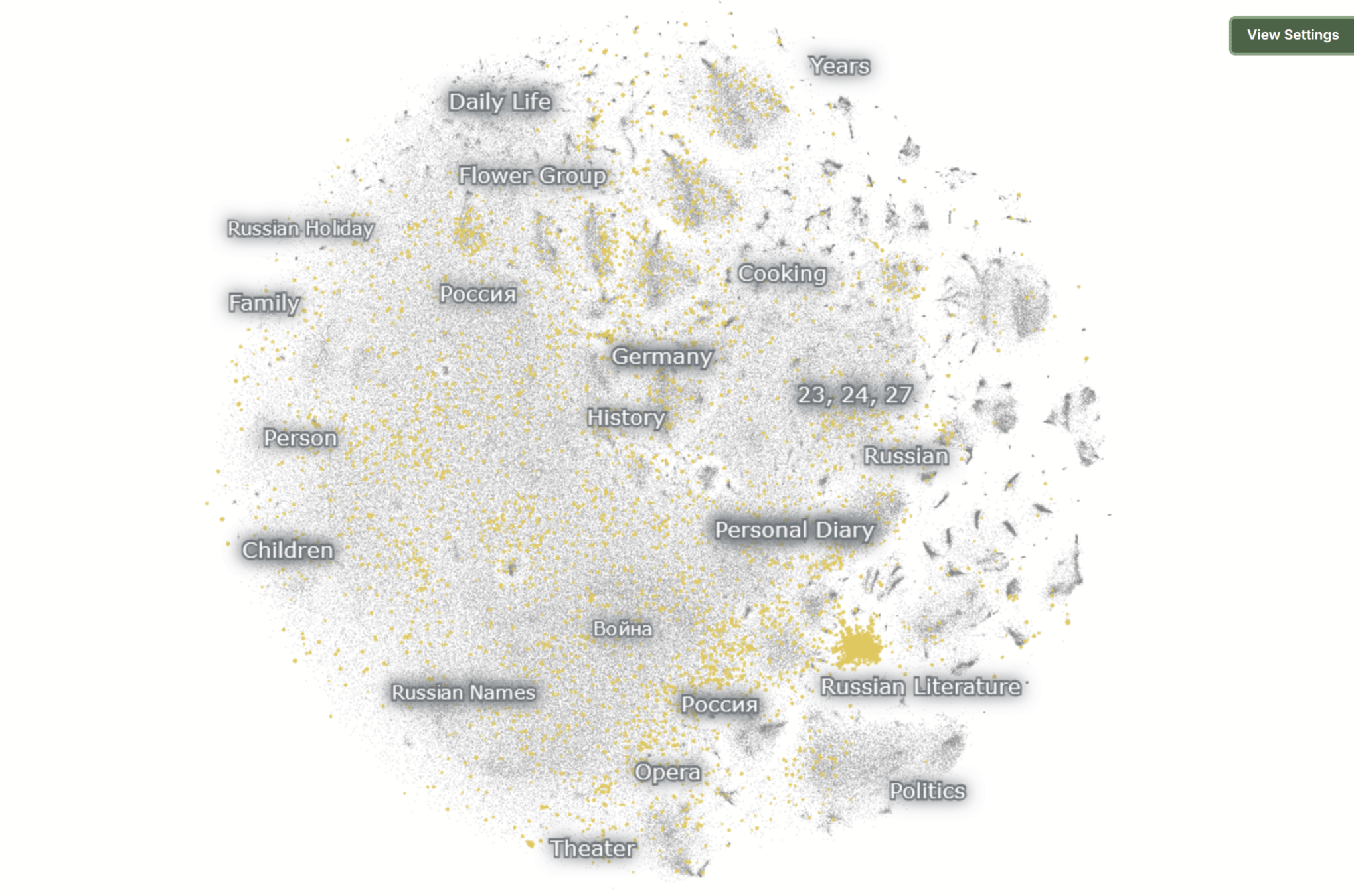
Person

stylistic
least coherent cluster: "Paris" (mixture of Russian and French)
Nomic topic: medium
5,349 diary entries
average inter-cluster distance: 26.500696
maximum distance: 75.331070

2305 Записей
thematic
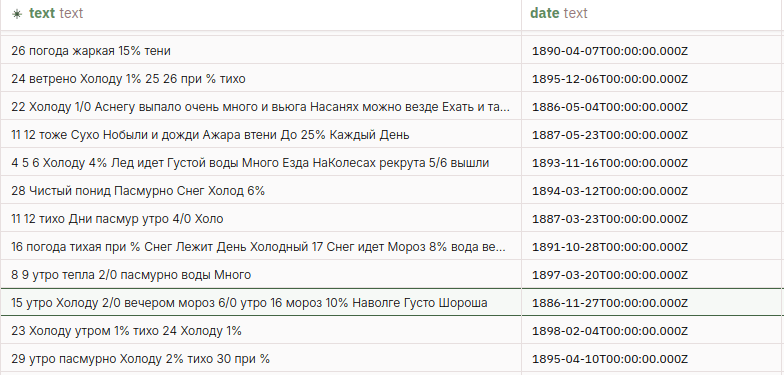
Length of Text
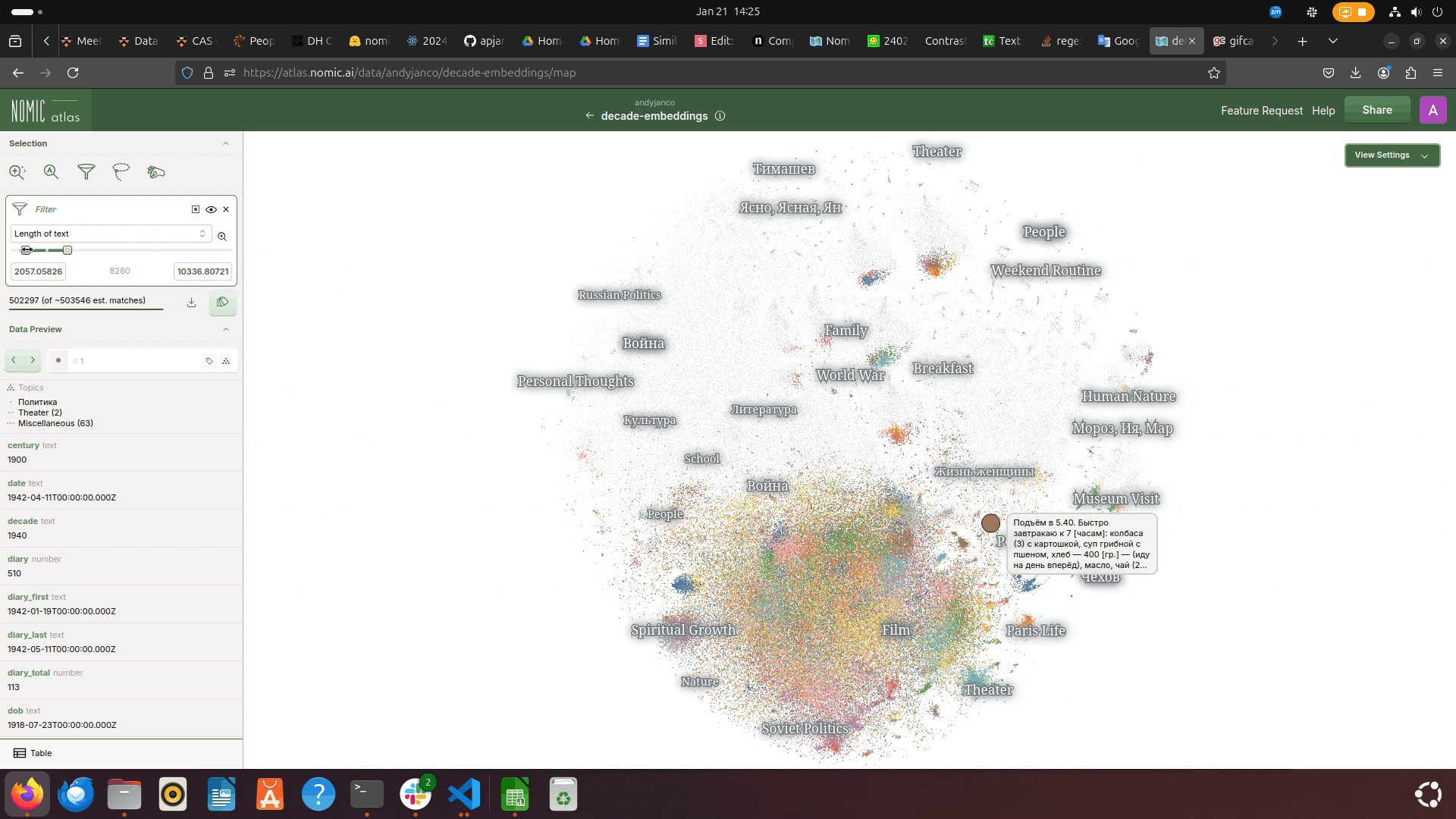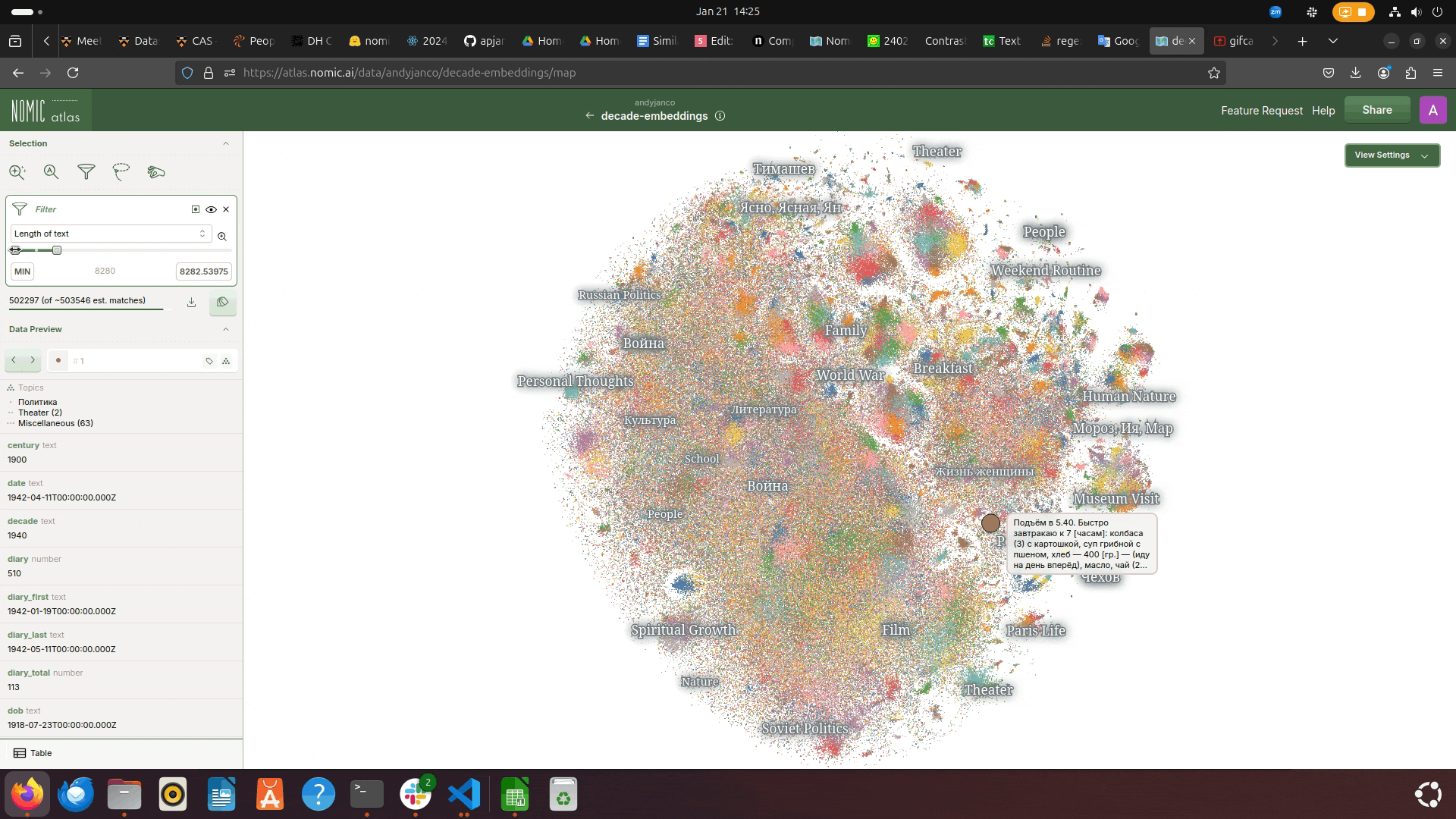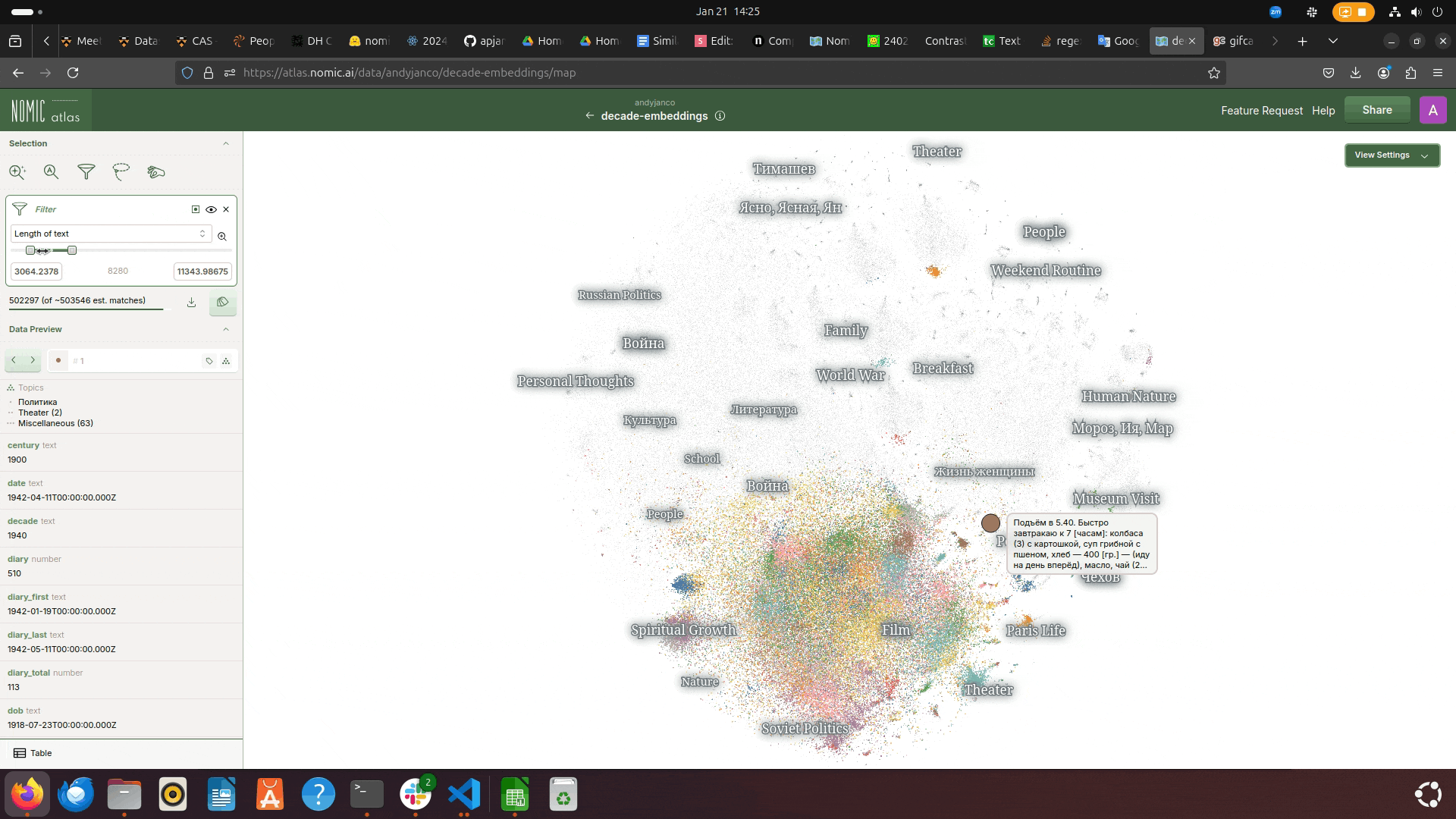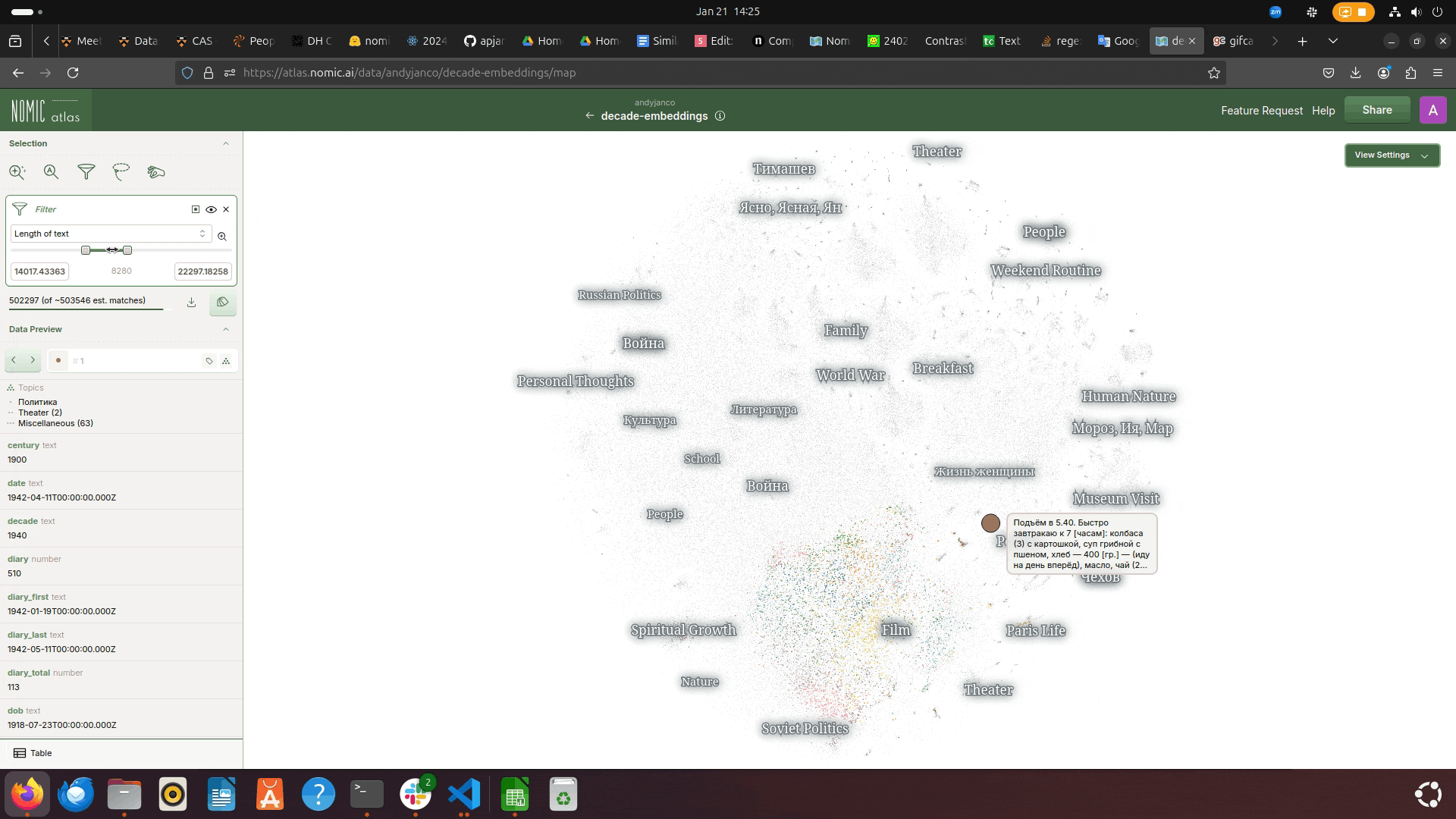
orthographic

So, "semantic similarity" is
similar meaning
and
lexical, orthographic, thematic,
and/or stylistic
similarity...
What can we do with that?
-
Identify patterns of diary writing across authors (clusters of like writing, for example, about weather or prices)
-
-
Re-use and citation of language, political phrases, and slogans as they appear in personal diaries – vector search for common Soviet slogans/sayings (самокритика, Работа над собой, ленин жил ленин жив...)
-
-
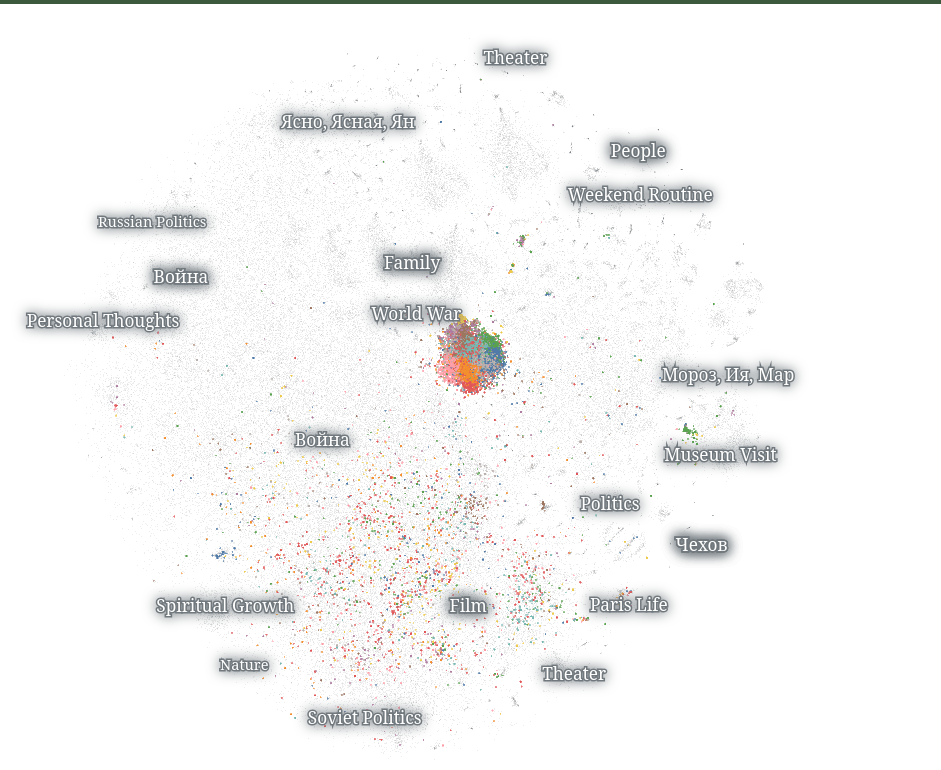
Uniformity/diversity of writing about war, specific experiences of war, and how they compare across multiple diary writers
-
-
Changing similarity over time. Identify diaries with high similarity at one time step, compute at other timesteps, and track how their similarity changes over time
lexical
〞
Thank you!
Bold
By Andrew Janco



