Predictive Modeling – Ensemble Learning
AdaBoost (Adaptive Boosting: Learning from Failure)

Learning Outcome
5
Compare AdaBoost's weighted voting system to a standard Random Forest.
4
Visualize the mathematical penalty applied to wrong predictions.
3
Calculate a model's "Amount of Say" based on its error rate.
2
Explain how AdaBoost adaptively changes the "Weight" of misclassified data.
1
Understand the concept of a "Decision Stump" as a weak learner.

The Cold Case Squad
A Chief of Police has a massive stack of unsolved cases.
He hires a team of detectives one by one to solve them
- Looks at the files, solves the easy ones, but completely fails the complex cases.
- He takes a giant red marker and circles the failed cases.
Detective 1 (The Rookie)
Looks at the files, solves the easy ones, but completely fails the complex cases.

He takes a giant red marker and circles the failed cases.
Detective 2 (The Specialist)
The Chief tells her, "Ignore the solved cases. Only look at the ones with red circles.
She solves a few, but misses the hardest ones. She draws an even bigger red circle around those


- When it's time to close the cases,
- The Chief asks all the detectives for their input. But he doesn't treat them equally.
- The highly accurate Specialist gets a massive say in the final decision, while the Rookie's vote barely counts.
This is AdaBoost! It forces new models to focus on the "red circles" (errors) and weighs their final votes based on their individual accuracy.
The Machine's Logic
The "Weak Learner" (The Stump)
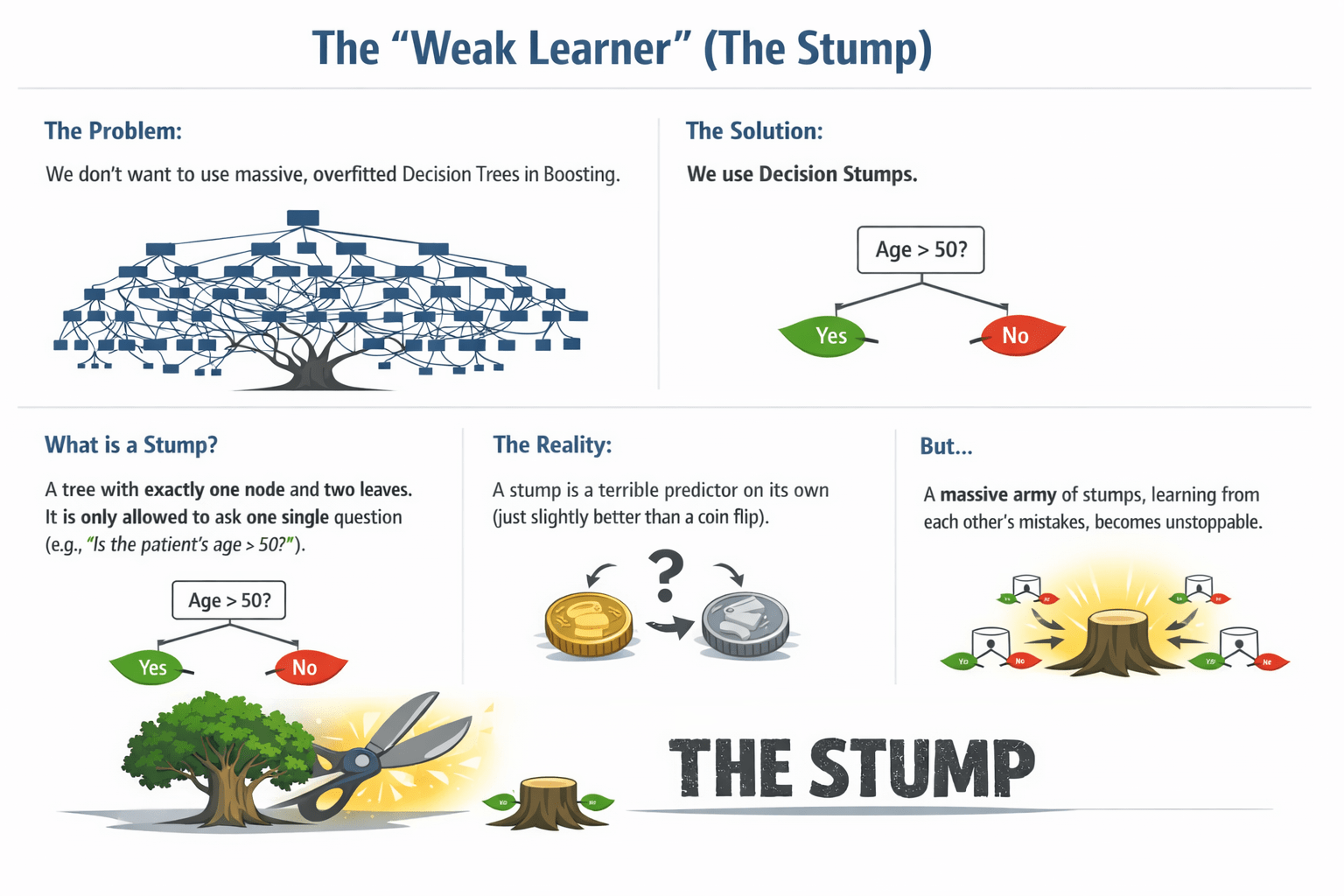
The Problem:
We don't want to use massive, overfitted Decision Trees in Boosting.
We use Decision Stumps
What is a Stump?
A tree with exactly one node and two leaves. It is only allowed to ask one single question
(e.g., "Is the patient's age > 50?").
The "Amount of Say" (α)
The Question: How much should we trust each stump's vote at the end?
-
We calculate the Amount of Say (α)
-
Based on the stump's Total Error (ε).
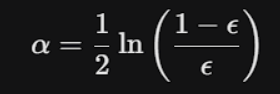
Breaking Down the Formula:
-
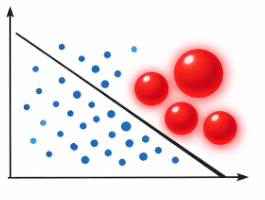
If the stump makes almost no mistakes (ε approx 0), its Amount of Say skyrockets to a massive positive number. (The Chief trusts it!).
- If the stump is basically flipping a coin (ε = 0.5), the formula outputs exactly 0. Its vote literally does not count.
- If the stump is intentionally wrong all the time (ε approx 1), it gets a massive negative say. (The Chief does the exact opposite of what it suggests!).

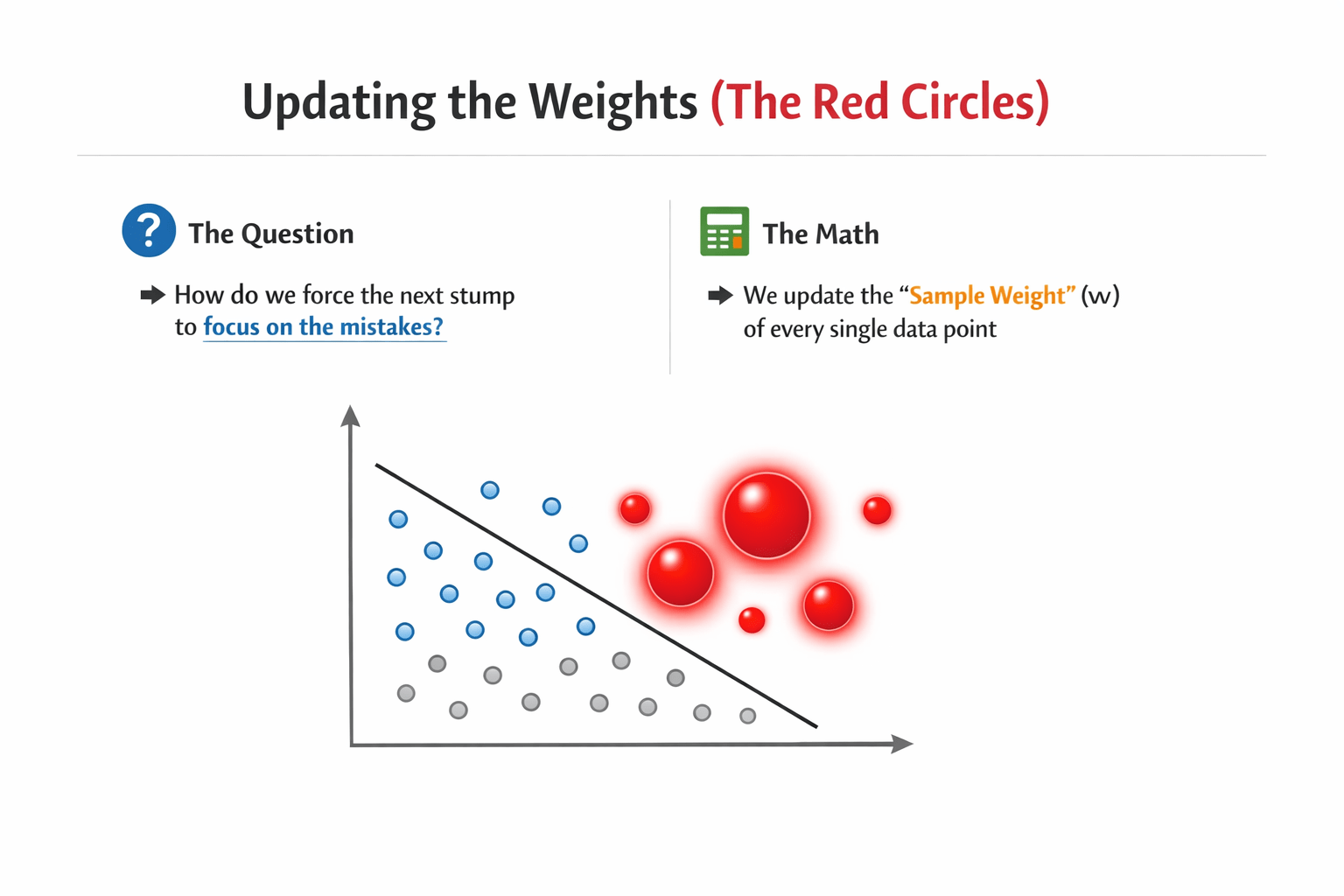
Updating the Weights (The Red Circles)
The Question: How do we force the next stump to focus on the mistakes?
We update the "Sample Weight" (w) of every single data point.
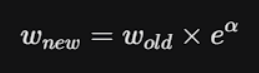
For INCORRECT predictions
(Making the red circle bigger)
e^{α} is greater than 1,
The weight of the mistake mathematically swells up, making it a massive priority for the next stump
Updating the Weights
The Question: How do we force the next stump to focus on the mistakes?
We update the "Sample Weight" (w) of every single data point.
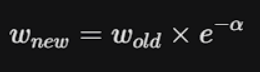
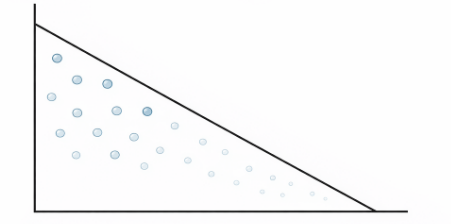
For CORRECT predictions (Fading into the background)
e^{-α} is fraction,
The weight of the solved cases shrinks, so the next stump ignores them.
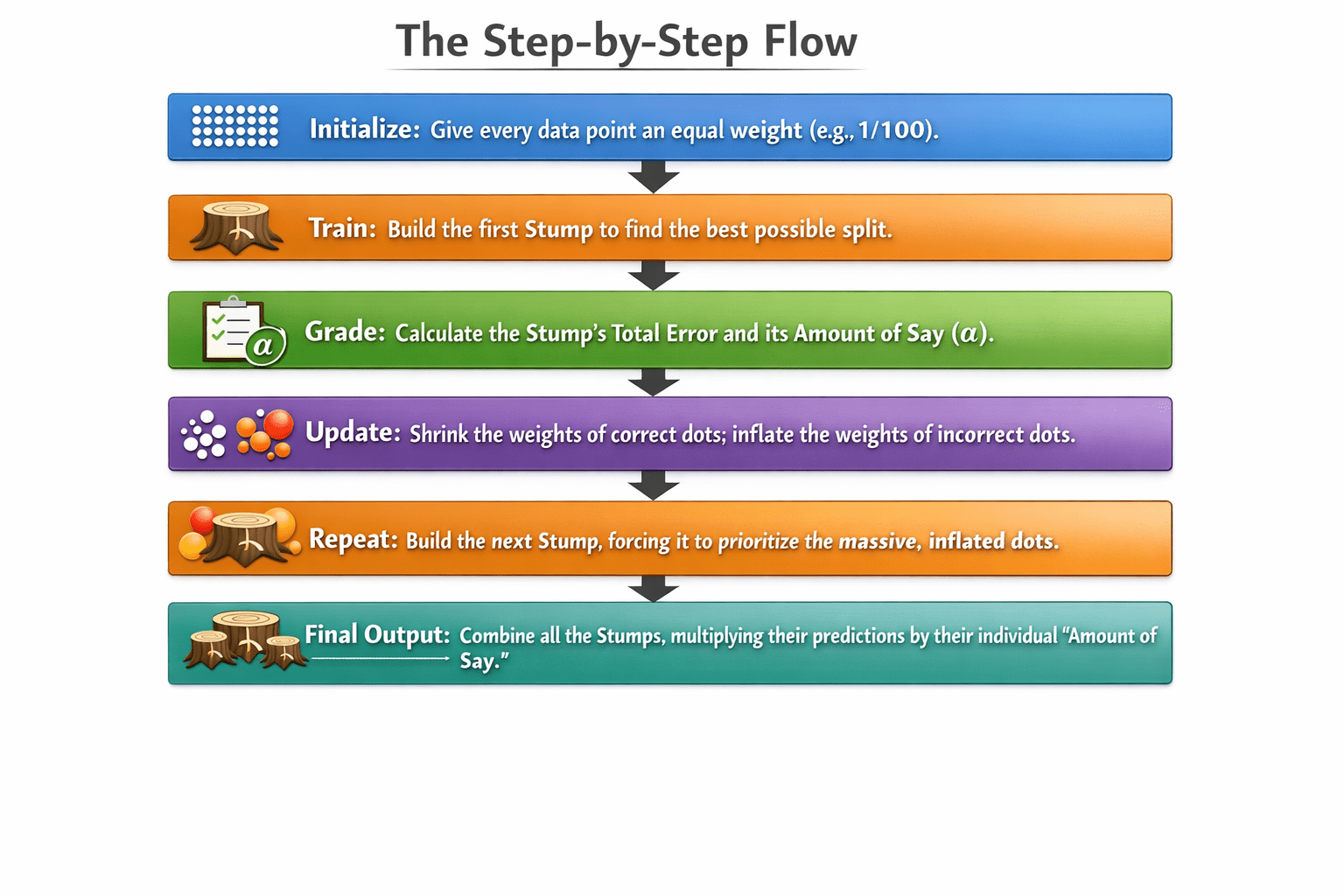
The Step-by-Step Flow
Initialize: Give every data point an equal weight (e.g., 1/100).
Initialize: Give every data point an equal weight (e.g., 1/100).
Initialize: Give every data point an equal weight (e.g., 1/100).
Initialize: Give every data point an equal weight (e.g., 1/100).
Initialize: Give every data point an equal weight (e.g., 1/100).
Initialize: Give every data point an equal weight (e.g., 1/100).
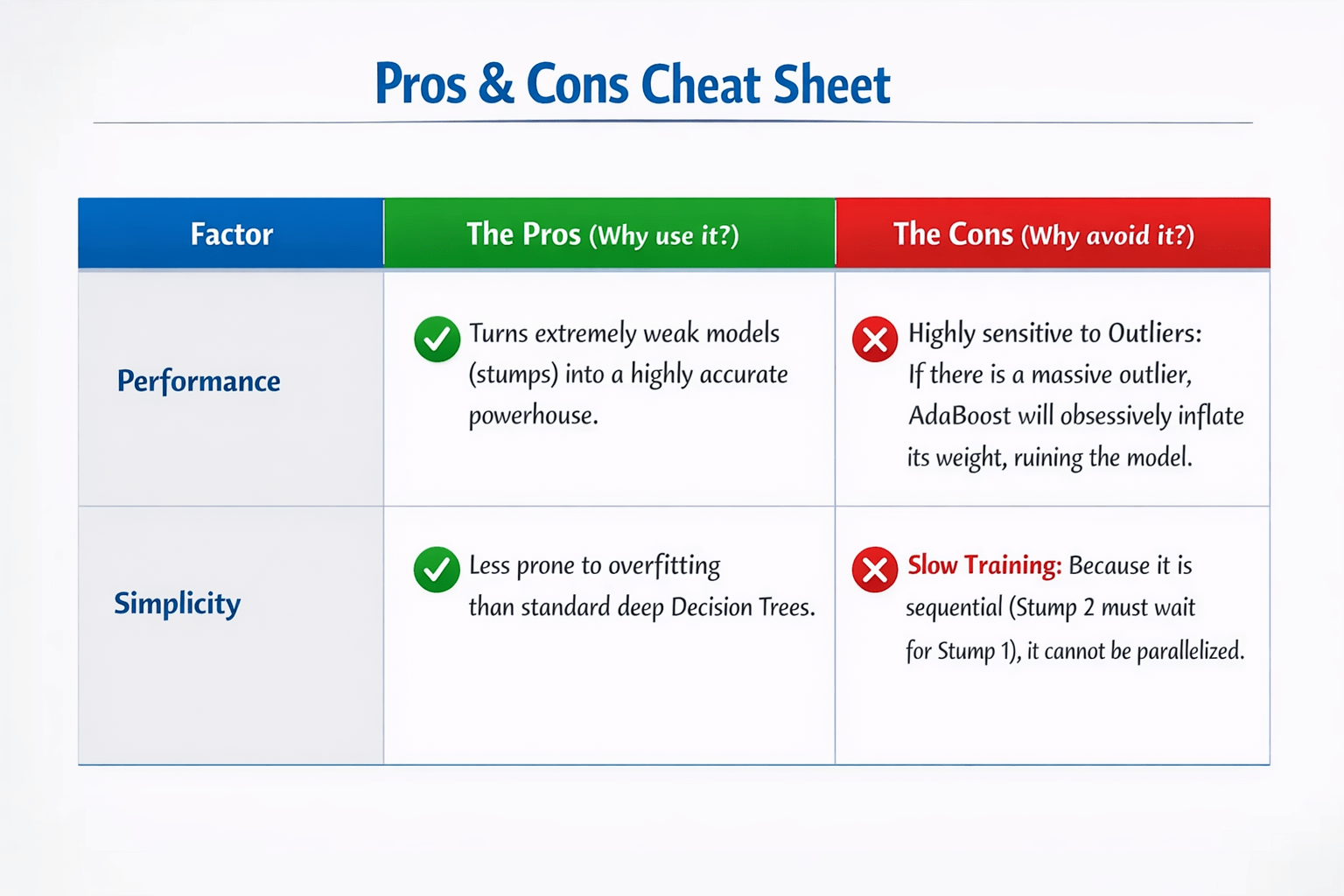
Turns extremely weak models (stumps) into a highly accurate powerhouse.
Less prone to overfitting than standard deep Decision Tree
Slow Training: Because it is sequential (Stump 2 must wait for Stump 1), it cannot be parallelized.
Highly sensitive to Outliers:
If there is a massive outlier, AdaBoost will obsessively inflate its weight, ruining the model
Summary
4
It is brilliant for clean data, but can be derailed by extreme outliers.
3
Wrong answers are multiplied by e^{α}, making them HEAVIER for the next stump
2
Highly accurate stumps get a LARGE “Amount of Say” (α) in the final vote.
1
AdaBoost uses a sequence of Decision Stumps (1-question trees)
Quiz
In AdaBoost, if a Decision Stump has a Total Error rate of exactly 50% (0.5), what will its "Amount of Say" (\alpha) be in the final ensemble vote?
A. 0.5
B. 1.0
C. 0 (Zero)
D. Infinity

In AdaBoost, if a Decision Stump has a Total Error rate of exactly 50% (0.5), what will its "Amount of Say" (\alpha) be in the final ensemble vote?
A. 0.5
B. 1.0
C. 0 (Zero)
D. Infinity
Quiz-Answer
