Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Prompt Inversion using Diffusion Large Langauge Models
Naresh Kumar Devulapally

Target: CVPR 2026
Fall 2025

What is Prompt Inversion?
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
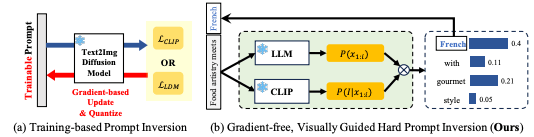
Given an input image (\( I_n \)) Prompt Inversion is the process of finding the optimal textual prompt (\( P \)) that, when fed into a pre-trained image generation model (\( G \)), would most faithfully reconstruct a given input image (\( I_n \))

(\( I_n \))
"A vibrant and colorful teapot with blue, red, orange, and green stripes, featuring an orange spout, handle, and feet, on a clean white background."
(\( P \))
Why Prompt Inversion?
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025



- Invert images to interpretable prompts.
- Utilize inverted prompts for image generation (Reusability).
- Style Transfer.
- Bridges vision ↔︎ language gap
- Few-shot efficiency
- Privacy-preserving: Encodes identity or proprietary visuals without sharing raw training data
- Distinct from editing: Goes beyond one-off pixel-level changes by giving a symbolic handle for semantic reuse.
A dog-faced backpack
Simple captions do not let you reproduce the object/style in images
Image Editing v/s Prompt Inversion
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025

(\( I_n \))
Image Editing: "Transform the realistic photo of the colorful teapot into a whimsical 2D children's book illustration that feels lively and enchanting."


Prompt Inversion
A whimsical and vibrant children's book illustration of a colorful teapot with blue, red, orange, and green stripes, featuring a playful orange spout, handle, and feet. The style is charming and expressive, with soft textures and a clean, inviting background, reminiscent of a classic storybook
Baseline Method
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025

Baseline Method: VGD
Baseline Experiments - VGD
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
'Pot, a vibrant and playful ceramic teapot set, with steam emitting from a small, handle-shaped pipe, sitting on a bright, striped, and bouncy surface next to 3 bright, multi-hued, water-based, plant-pot-shaped, plastic, toy, water-injected, water-based water balloon-shaped water-injected plastic.'


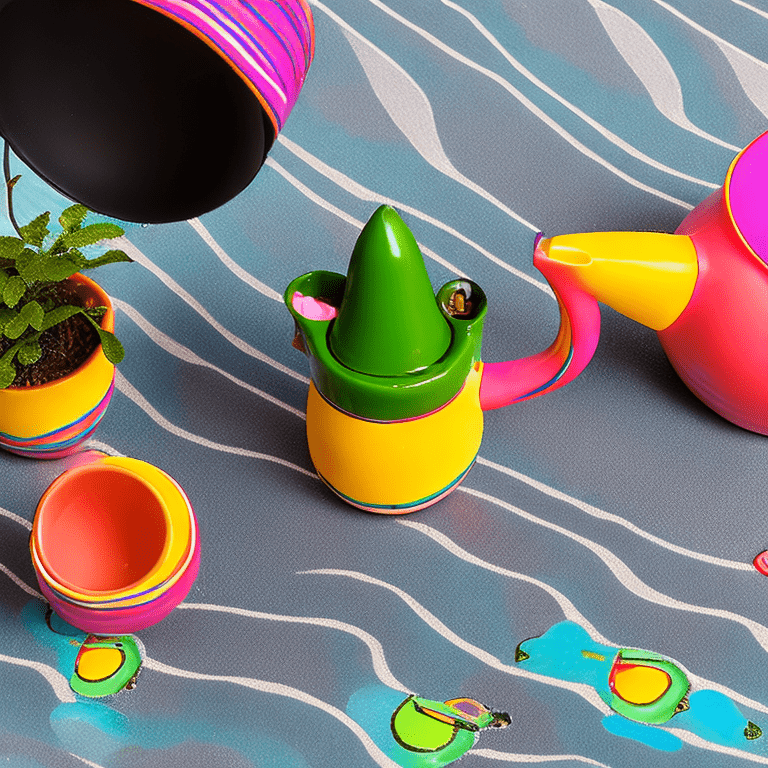


Week 1: Task - Soft Prompting in SD 3.5
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
- No existing implementation for Textual Inversion in SD 3.5 medium.
Question: Does Soft Prompting tokens allow for additional conditioning for personalization?





s_*
A photo of \( s_* \) dog
Week 1: Task - Soft Prompting in SD 3.5
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
Question: Does Soft Prompting tokens allow for additional conditioning for personalization?

A photo of \( s_* \) dog beside a cat.

A photo of \( s_* \) dog beside a white cat.

Hard
Prompt Inversion
with 1 image
Week 1: Task - Replace Llama with LLada (Inf. Speed up)
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025

Input
VGD - LLama

VGD - LLada - Block Size 32

VGD - LLada - Block Size 16

VGD - LLada - Block Size 1
32 \( \times \) Speed up*
32 \( \times \) Speed up*
No Speed up*
* Approximate calculations
(Full LLada generation)
Baseline Experiments - VGD
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025


LLaDa - Block size 32
Baseline Experiments - VGD
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
LLaDa - Block size 32
October 9 - Weekly
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
- LLaDA-V significantly improves inference time for Prompt Inversion.
- Without Steering - 20.5x faster for 32 token generation.
- With Steering - 6x faster for 32 token generation.
- We beat VGD on all text metrics with 4% lower image clip score (without steering), 2% lower with steering.
- Results Google Sheet: Here
- Few Step Generation with LLaDA-V
- Implemented DDIM style few-step inference with LLaDA-V
- 4 - steps - 0.71 seconds - Bad scores
- 6 - steps - 0.80 seconds - Bad scores
- 10 - steps - 0.95 seconds (40x improvement) - same scores as 128 steps.
- Implemented DDIM style few-step inference with LLaDA-V
October 9 - Weekly
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
- User Studies for validation of generated prompts
- Designed three user studies
- Image - Prompt Alignment
- 3 users - 74% ours - 22% VGD - 4% Neither
- Image regeneration user study
- 1 user - 60% - ours, 40% - VGD
- Personalization user study
- Concept swap user study
- Image - Prompt Alignment
- Designed three user studies
How can we validate our generated prompts?
Milestone 1 - To-Dos
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
-
Methods section:
- LLaDA for prompt inversion - base 1
- FK Steering with LLaDA - base 2
-
Remasking w/o FK Steering for editability - base 3
- Concept Fusion, Gating, Orthogonalization etc.
-
Remasking with FK Steering for editability - base 4
- Same as above but with FK Steering.
- Few steps LLaDA - No FK steering - base 5
- Few steps LLaDA - FK steeering - base 6
-
Experiments section:
-
Quantitative Results
- I.1. Text level metrics, I.2. Image level metrics
-
Qualitative Results
- Image Reconstruction results
-
Prompt Editing
- Concept Append, Concept Swap
-
Quantitative Results
October 17 - Weekly
Naresh Kumar Devulapally
Prompt Inversion - DLLMs
Fall 2025
- Completed so far:
- LLaDA based prompt generation
- Speed up advantages (20x, 32 tokens)
- LLaDA + FK Steering
- Text and Image similarity metrics advantages
- Speed trade off (10x, 32 tokens)
- LLaDA based prompt generation
- Method related:
- Splitting prompt into concepts (subject, background, style)
- Apply timestep-aware denoising strategy for each concept with concept-overlap loss
- Intuition: Low cross-concept overlap might lead to better concept swap personalization.
- Results: Qualitative Results show improvements over VGD.
- Token level overlap:
- Implement the concept overlap idea to token level and result in low token overlap.
Prompt Inversion using Diffusion LLMs
By Naresh Kumar Devulapally



