Black Holes Neural Network II
Ref Bari
-
Define experiment parameters
- Initial parameters vector (with 4 orbital elements)
- Define time span
- Masses of black holes
-
Gather Waveform Data
- Use `file2trajectory` to convert .txt to (x, y) data
- Use `file2waveform` to convert .txt to waveform
-
Create two separate neural networks for the angular parameters (chi, phi) and the (p, e) parameters
- Why separate? Try creating one big network
- Why is there tanh in the neural network definition?
- Why two dense layers for the neural networks?
-
Initialize the Neural Networks
- Initialize the Neural Networks with Random #s
- Initialize the (weights, biases) vector = 0
-
Adapter Functions
- Create two adapter functions so that the chiphi neural net and the pe neural nets are compatible with the arguments accepted by ODE_model
- Concatenate the chiphi and pe parameters into NN_params
-
ODE Problem
- Feed initial vector u + parameters into AbstractNROrbitModel
- Return du (what's du?) from function ODE_model
- Feed ODE_model into prob_nn
- Feed prob_nn into soln_nn
- Feed soln_nn into compute_waveform
-
Objective Loss Function
- pred_soln: Use solve function to solve prob_nn (again? why?)
- Compute GW from pred_soln using compute_waveform
- Store p and e from predicted solution into p and e
- Calculate loss using regularization terms
-
Train Neural Network
- Define an optimization_increments array which decides when to optimize the network
- In a for loop, define a tsteps_increment array which steps the time forward using t = t0 + i*dt, where i = increment #
- Calculate loss and store in tmp_loss() function
- Use opt_callback() to take the current state of the neural network, then push everything into tmp_loss(p)
- pred_orbit: Plug in the pred_soln into soln2orbit
- orbit_nn1, orbit_nn2: plug in pred_orbit into one2two
- Assign χ, ϕ to pred_soln[1/2,:] and p,e to pred_soln[3/4,:]
- Define a global NN_params (why? we already got NN_params)
- Define the optimization problem using scalar_loss
- Run BFGS training algorithm separately for Iterations 1-99, 99, and 100 (with different learning rate for each)
- What if you initialize parameters u0 differently?
- Where is tsteps used? (L33)
- What if you change tspan? (L31)
- What if you change num_optimization_increments?
- Why does model_params (L38) have only the mass_ratio?
- How does file2trajectory work?
- How does file2waveform work?
- What if you change the ansatz functions in NN_chiphi & NN_pe?
- Can you get rid of the adapter functions by modifying AbstractNROrbitModel instead?
- What if you change the regularization parameters in the loss function?
- Experiment with optimization_increments?
- What if you initialize parameters u0 differently?
- Where is tsteps used? (L33)
- What if you change tspan? (L31)
- What if you change num_optimization_increments?
- Why does model_params (L38) have only the mass_ratio?
- How does file2trajectory work?
- How does file2waveform work?
- What if you change the ansatz functions in NN_chiphi & NN_pe?
- Can you get rid of the adapter functions by modifying AbstractNROrbitModel instead?
- What if you change the regularization parameters in the loss function?
- Experiment with optimization_increments?
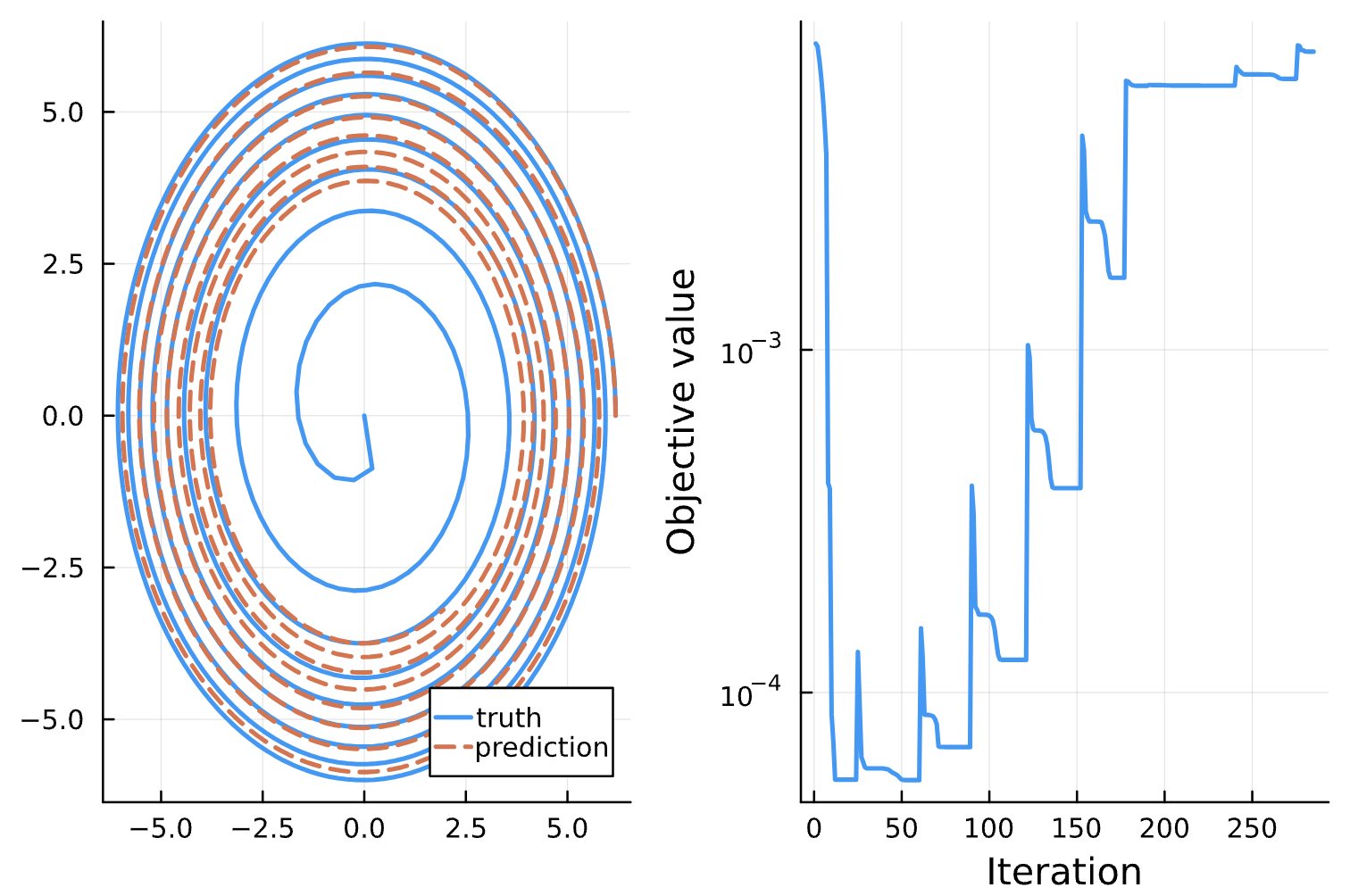
Change: NN_chiphi has only one dense layer with ansatz cos(chi)
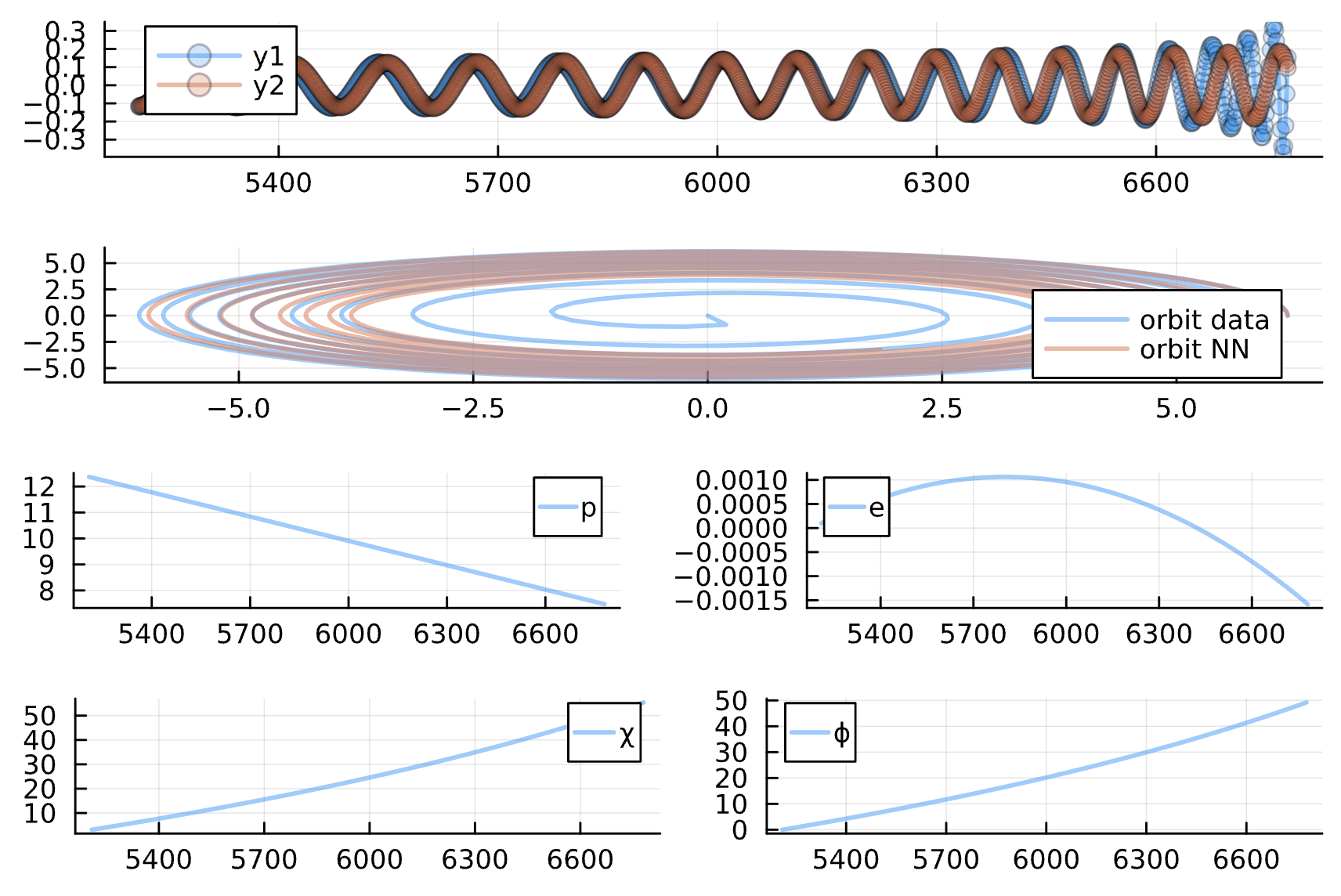
Change: NN_chiphi has only 1 dense layer with ansatz cos(chi)
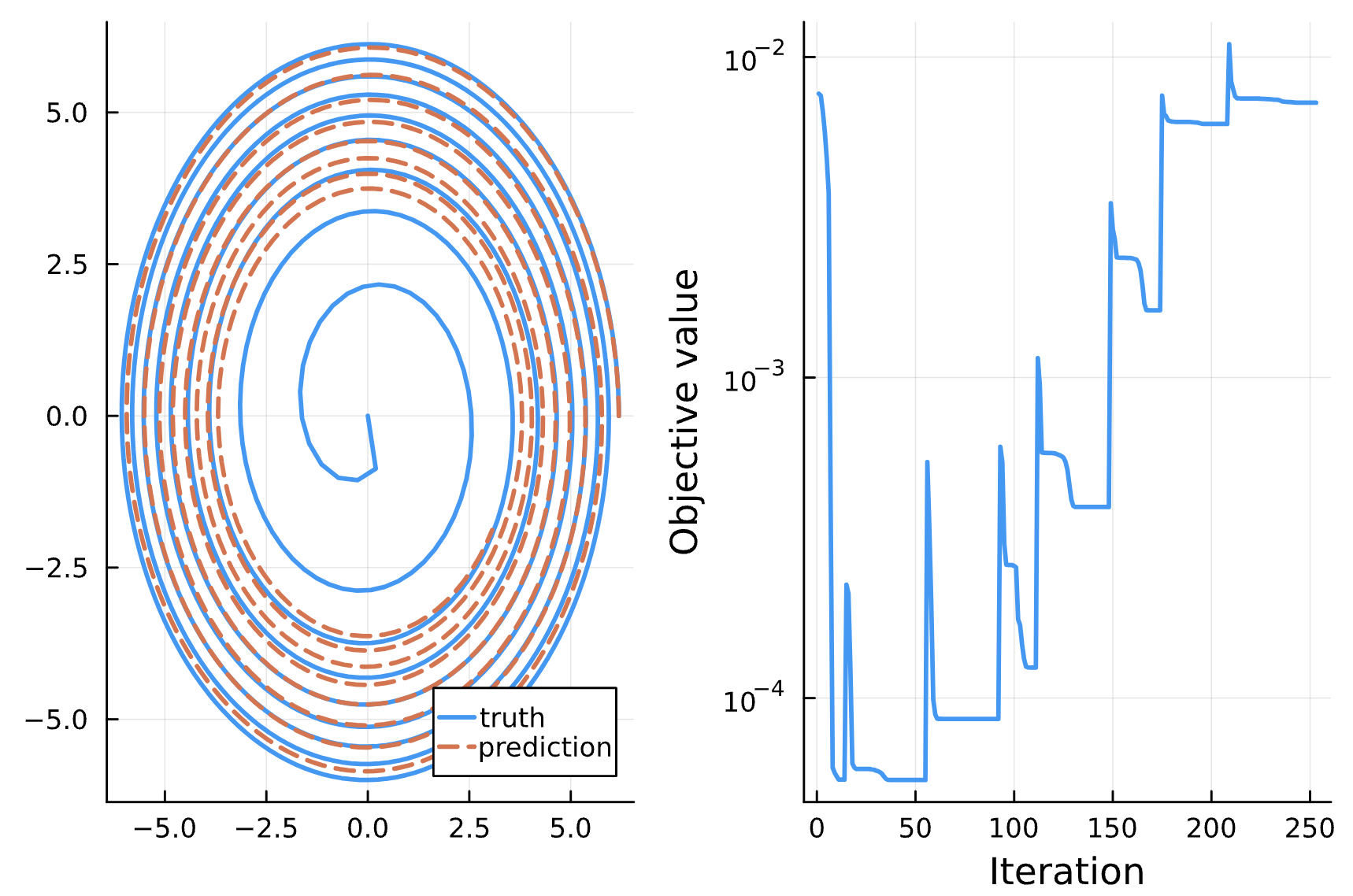
Change: NN_chiphi has 4 dense layers with ansatz chi, phi, p, e
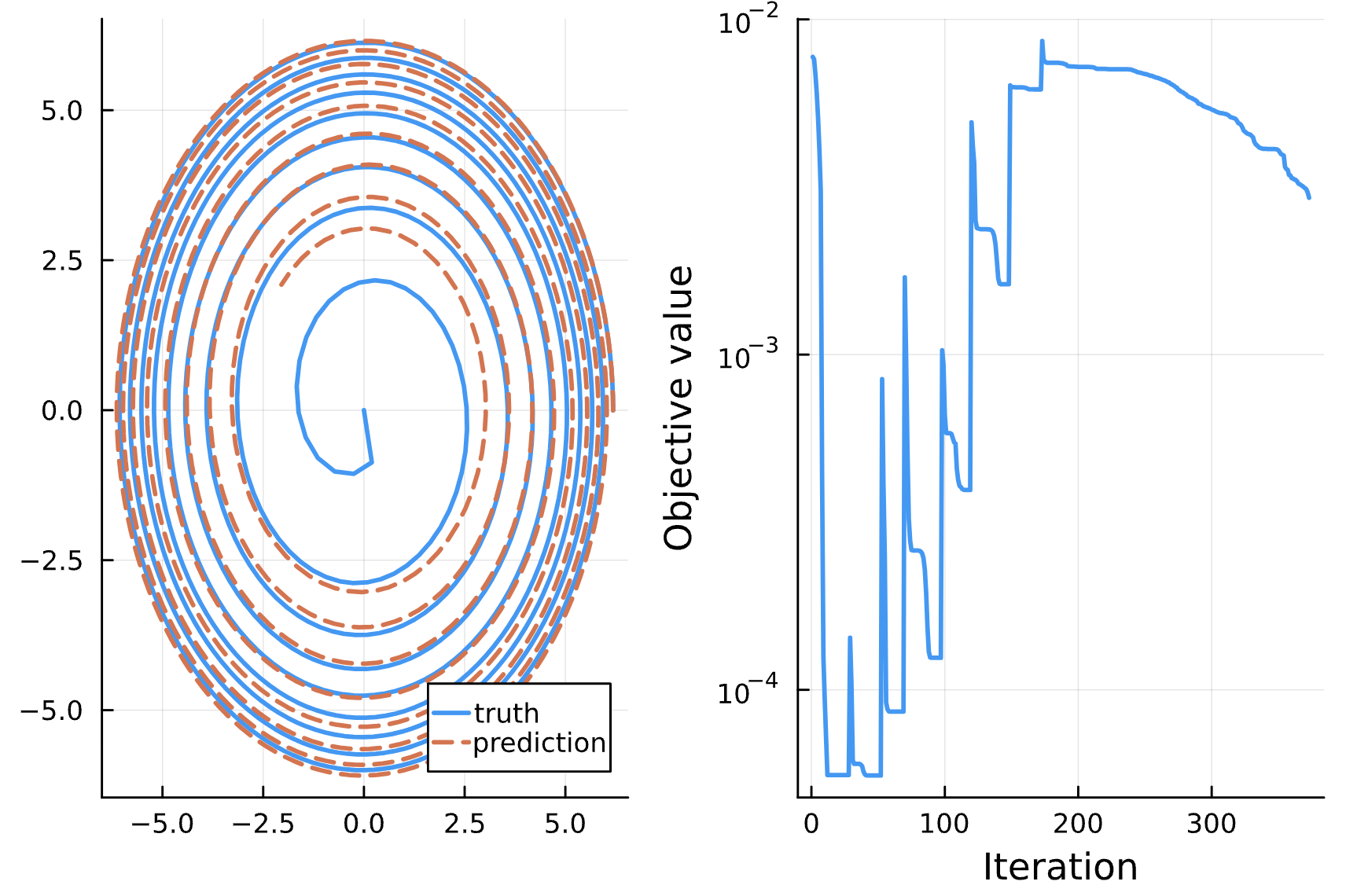
Change: NN_chiphi has 5 dense layers with ansatz chi, phi, p, e, cos(chi)
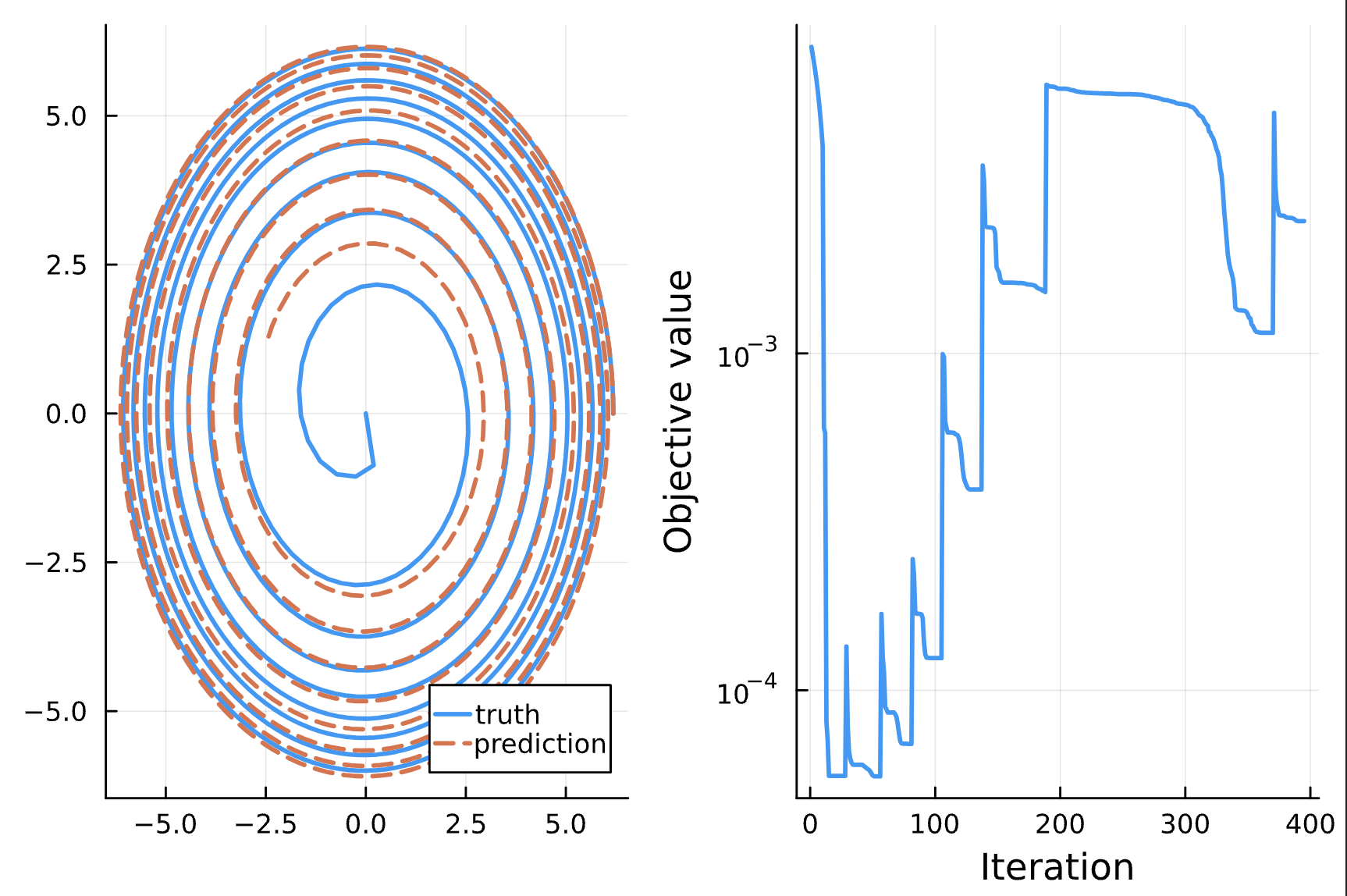
Change: NN_chiphi has 6 dense layers with ansatz chi, phi, p, e, cos(chi), sqrt(p)^3
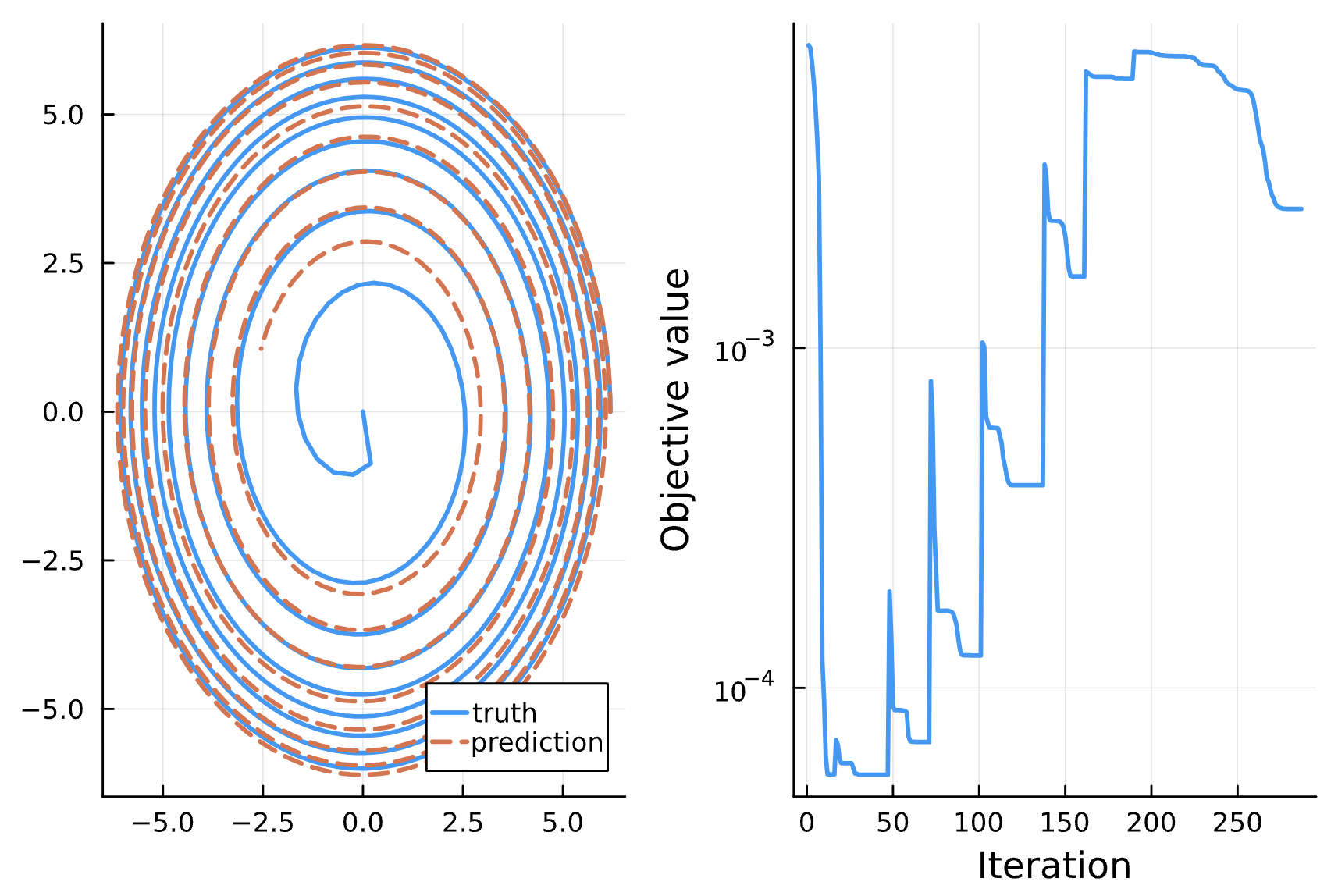
Change: NN_chiphi has 6 dense layers with ansatz 1/p, p^2, p, e, cos(chi), sqrt(p)^3
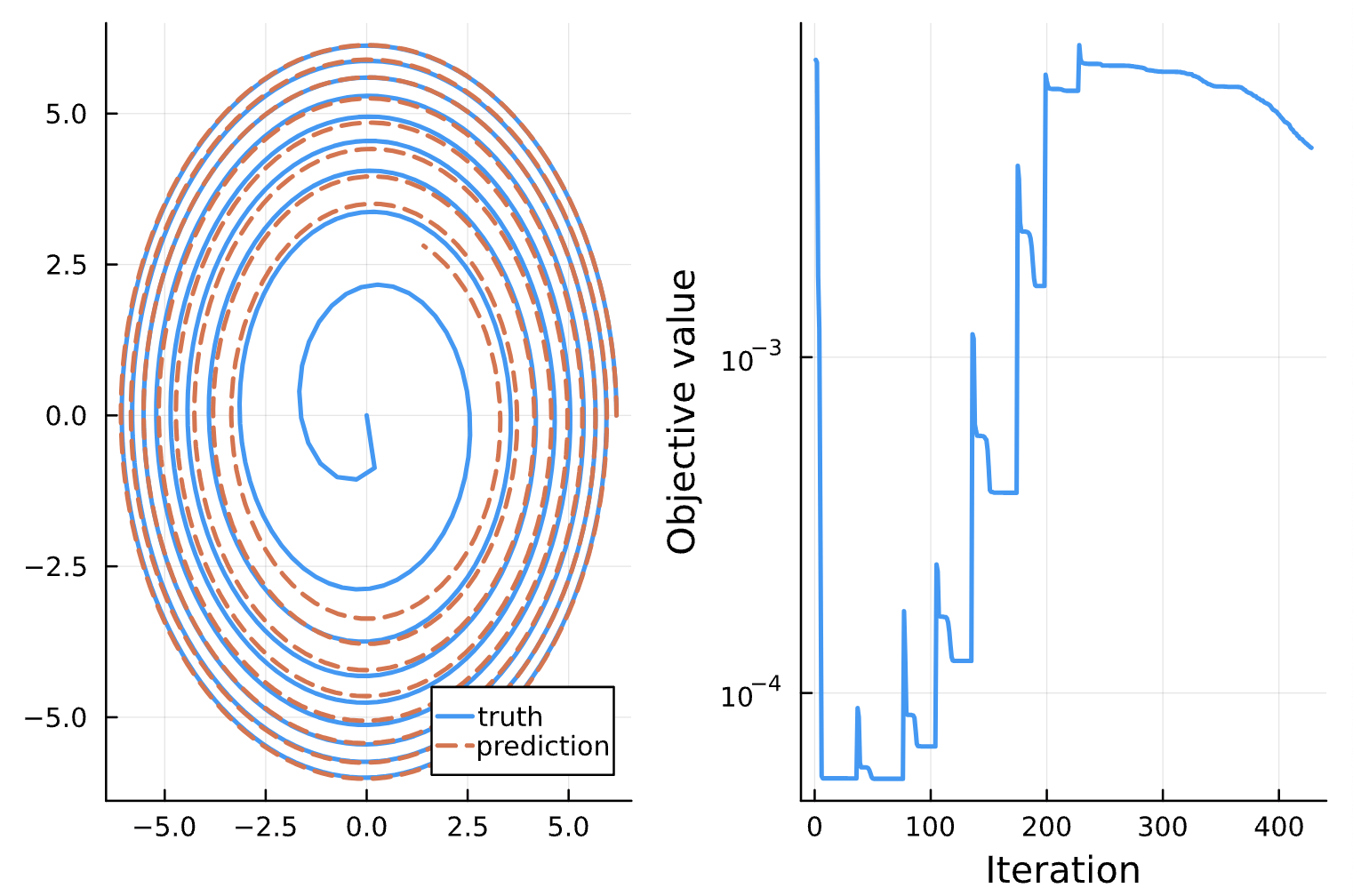
Change: NN_chiphi has 8 dense layers with ansatz 1/p, p^2, p, e, cos(chi), sqrt(p)^3, 1/sqrt(p), sqrt(p)
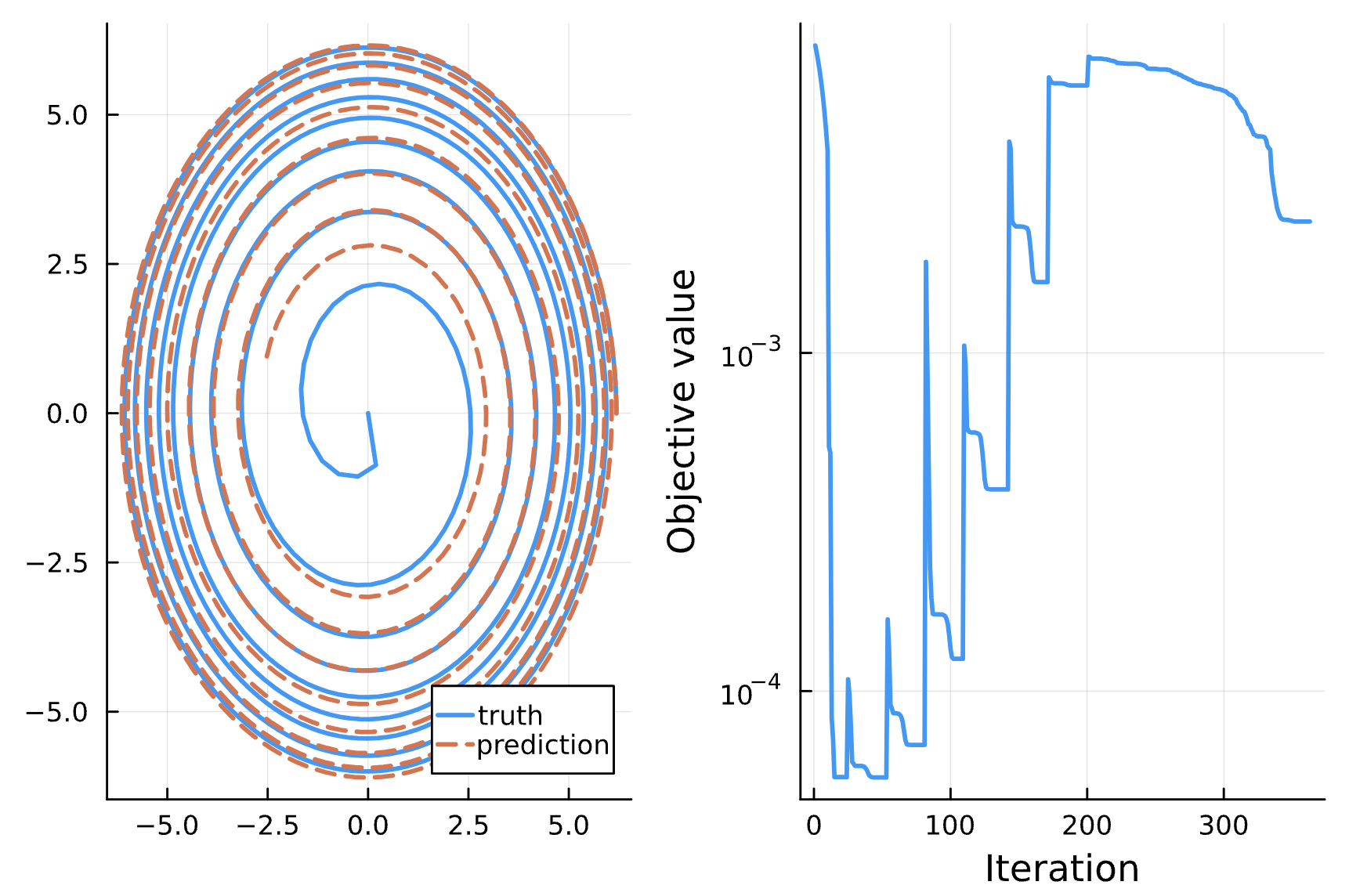
Change: NN_chiphi has all 9 dense layers
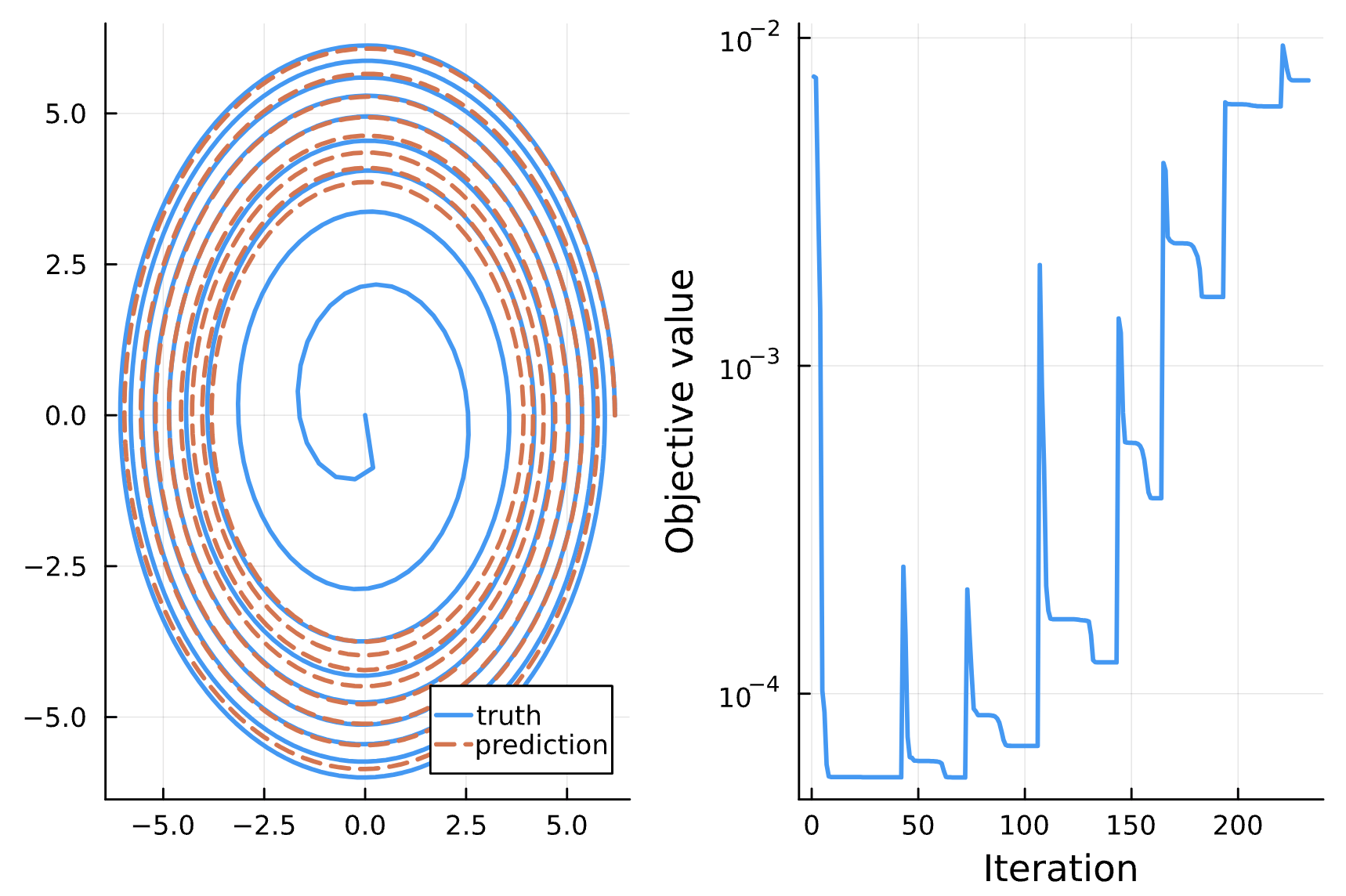
Change: Removed e[p > 6 + 2*chi] - chi > 0 constraint
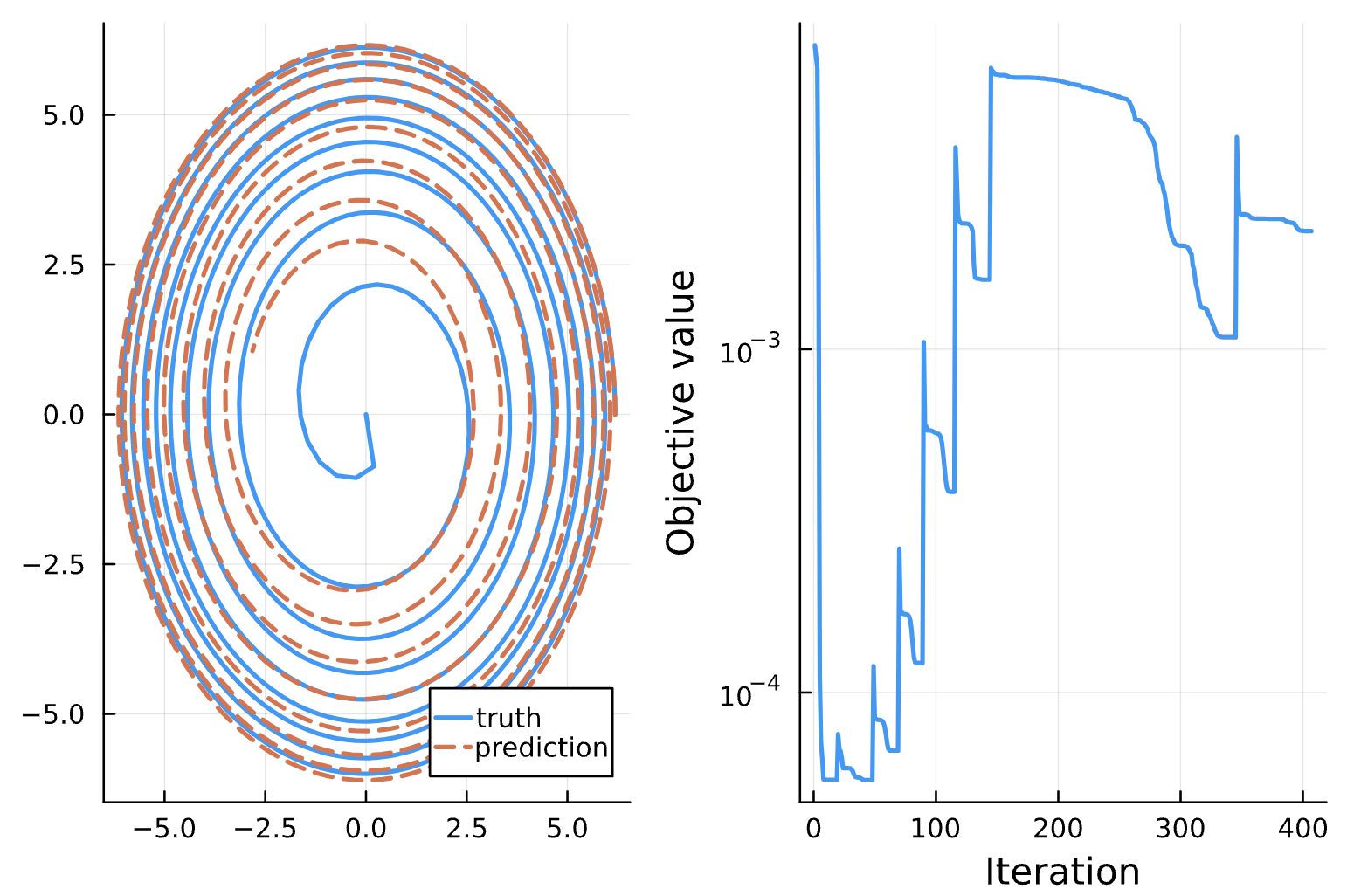
Change: Added (d/dt)^2(e) > 0 (1.0f2 L, 1.0f0 R)
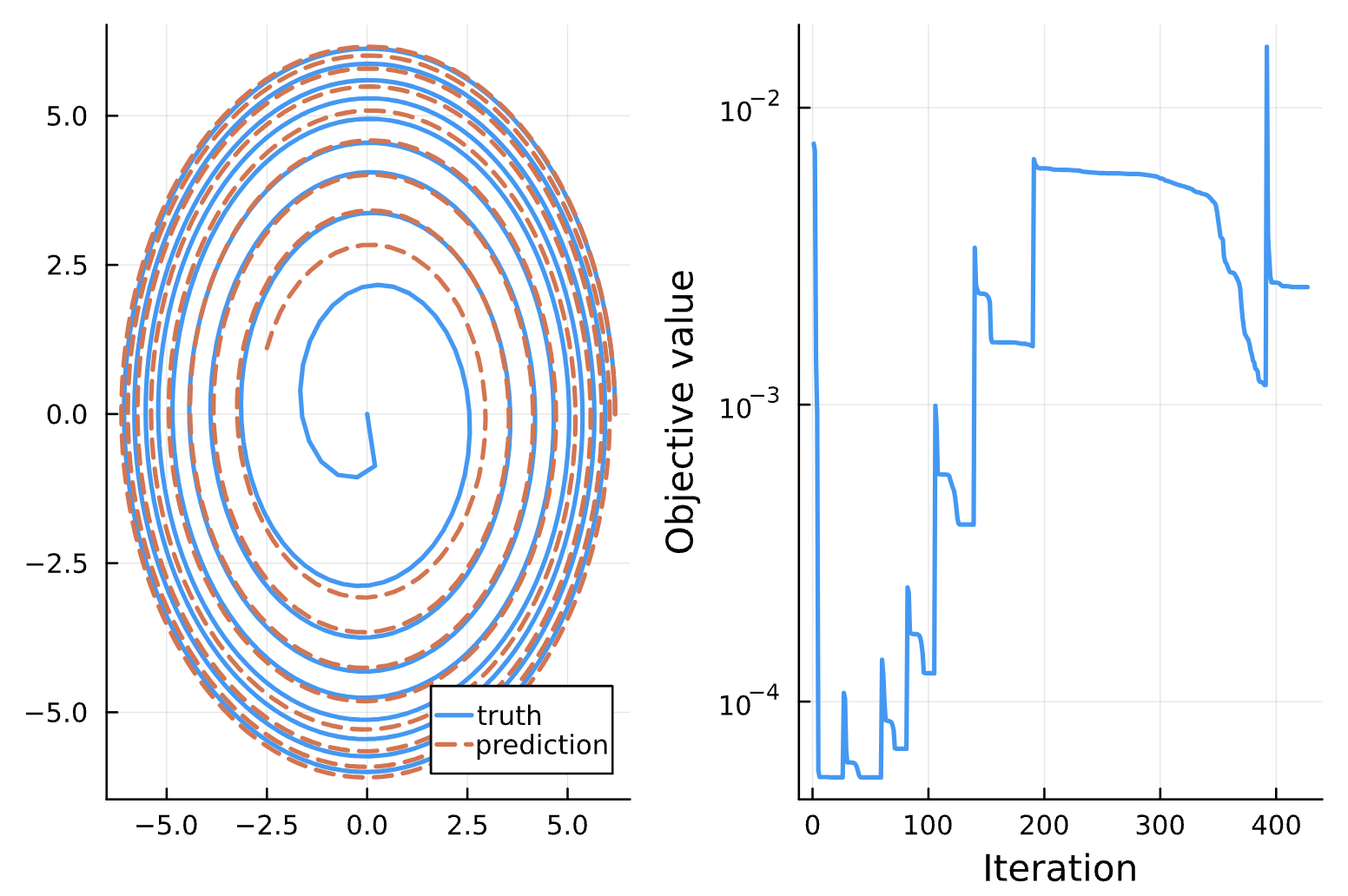
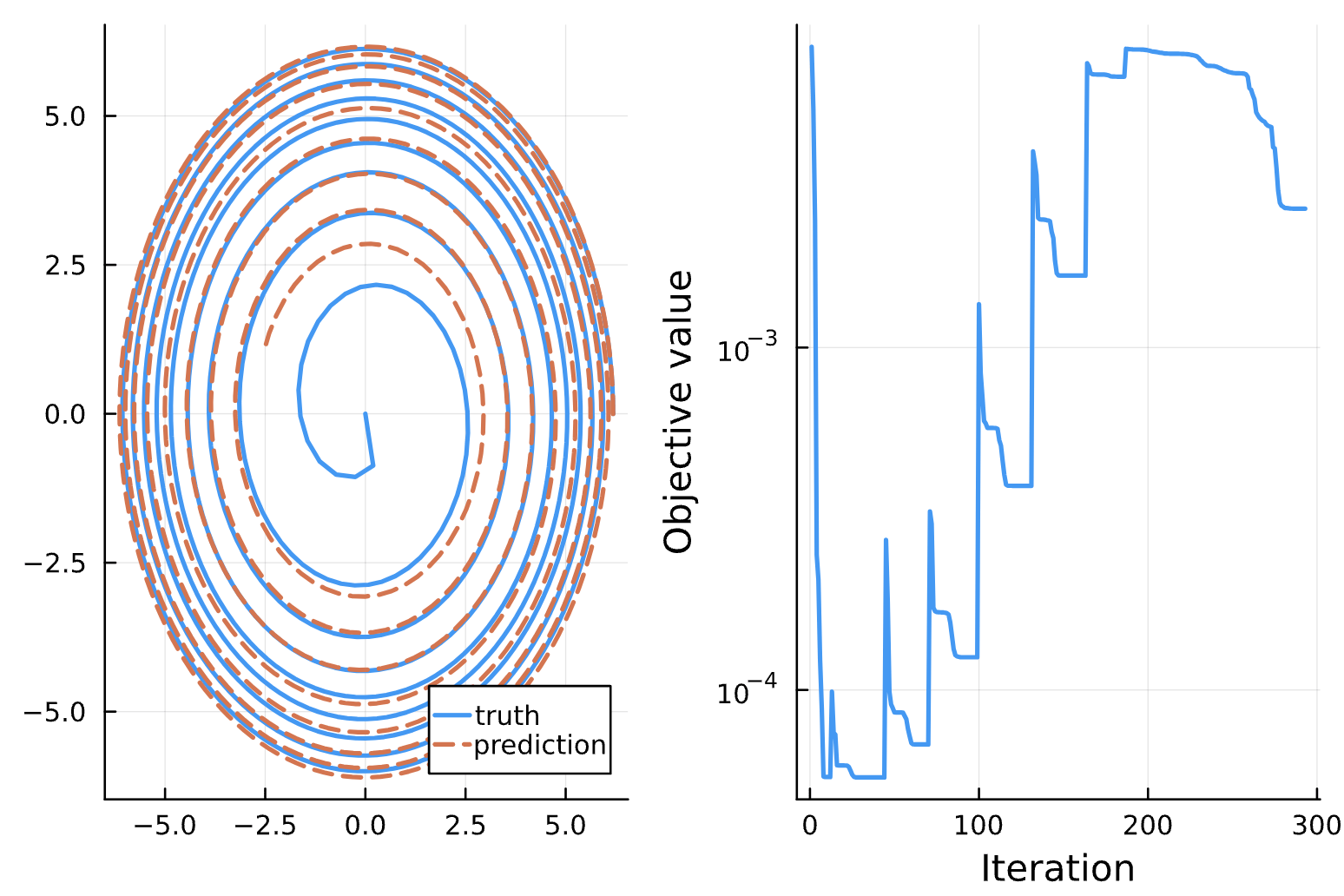
Change: Noise = 1e-1 (a), 1e-2 (b), 1e-3 (c), 1e-4 (d)
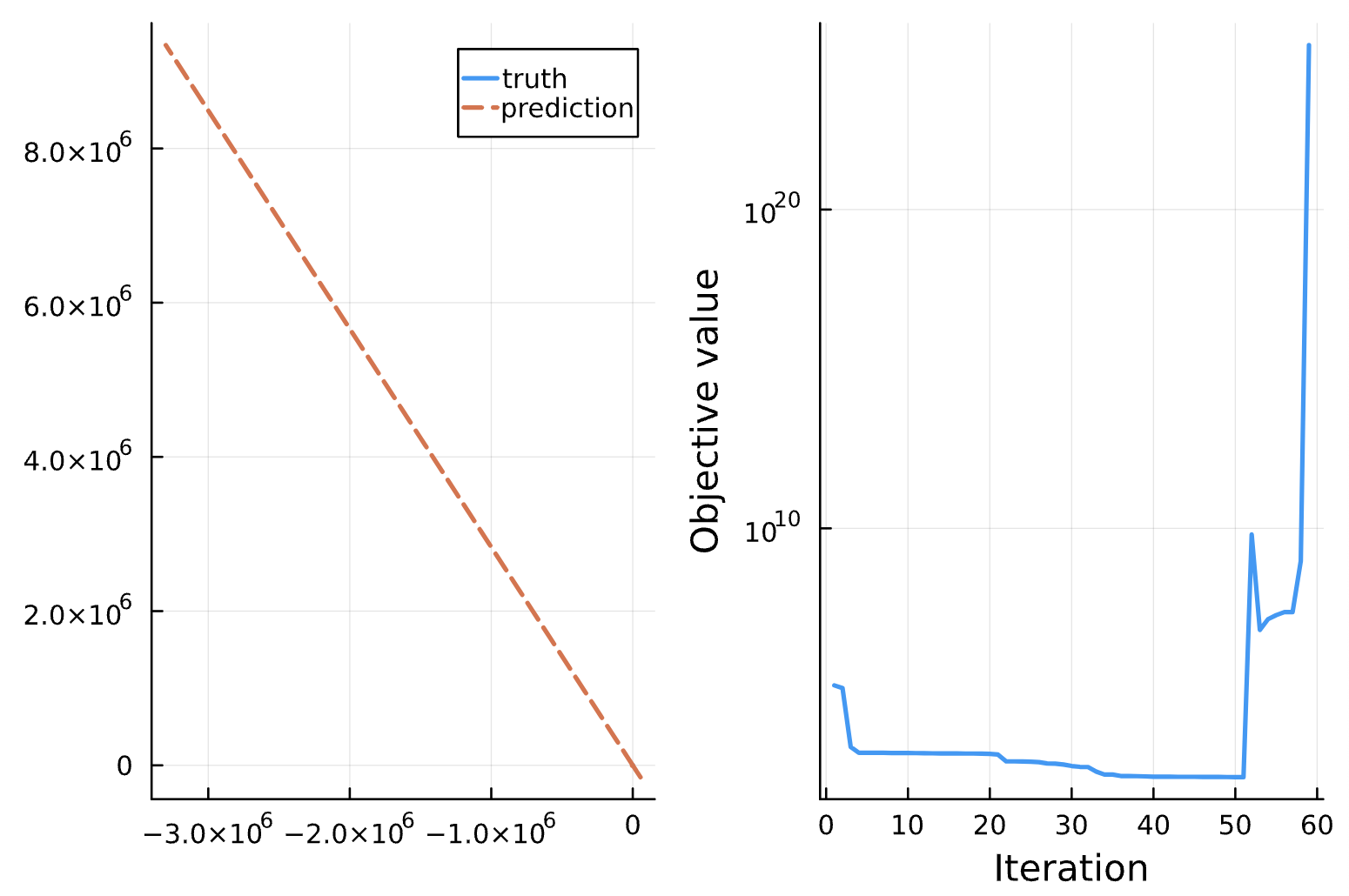
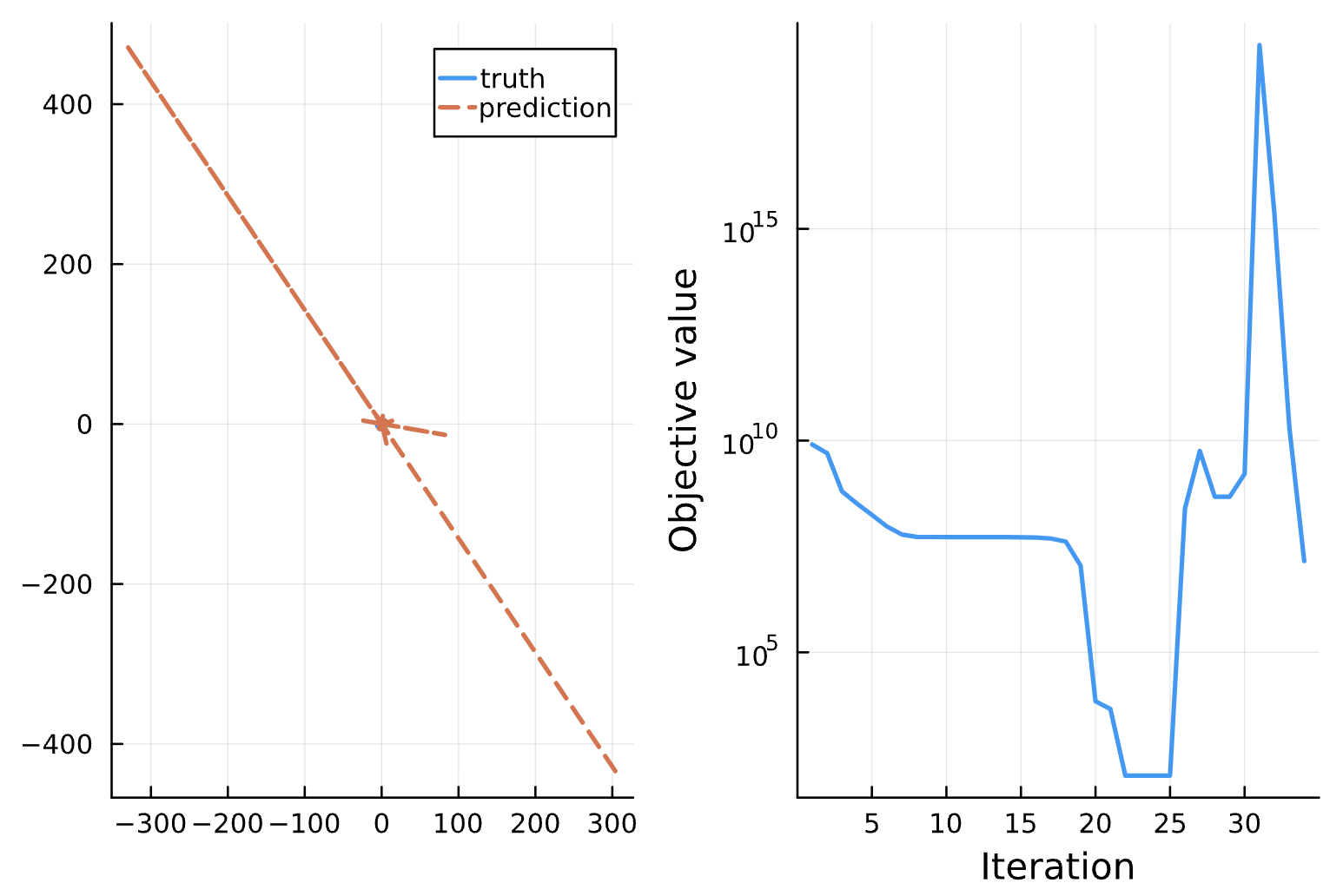
(a)
(b)
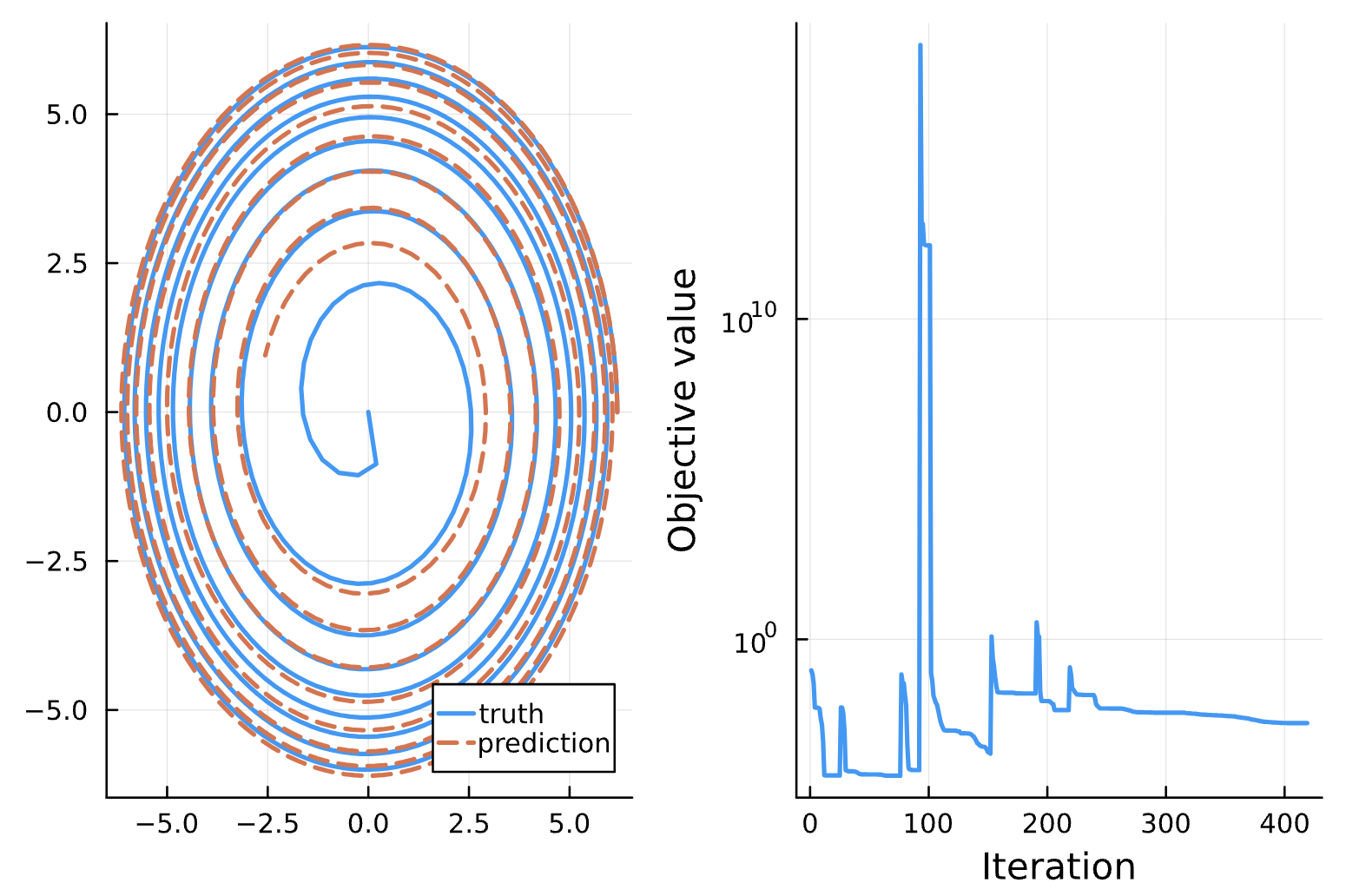
(c)
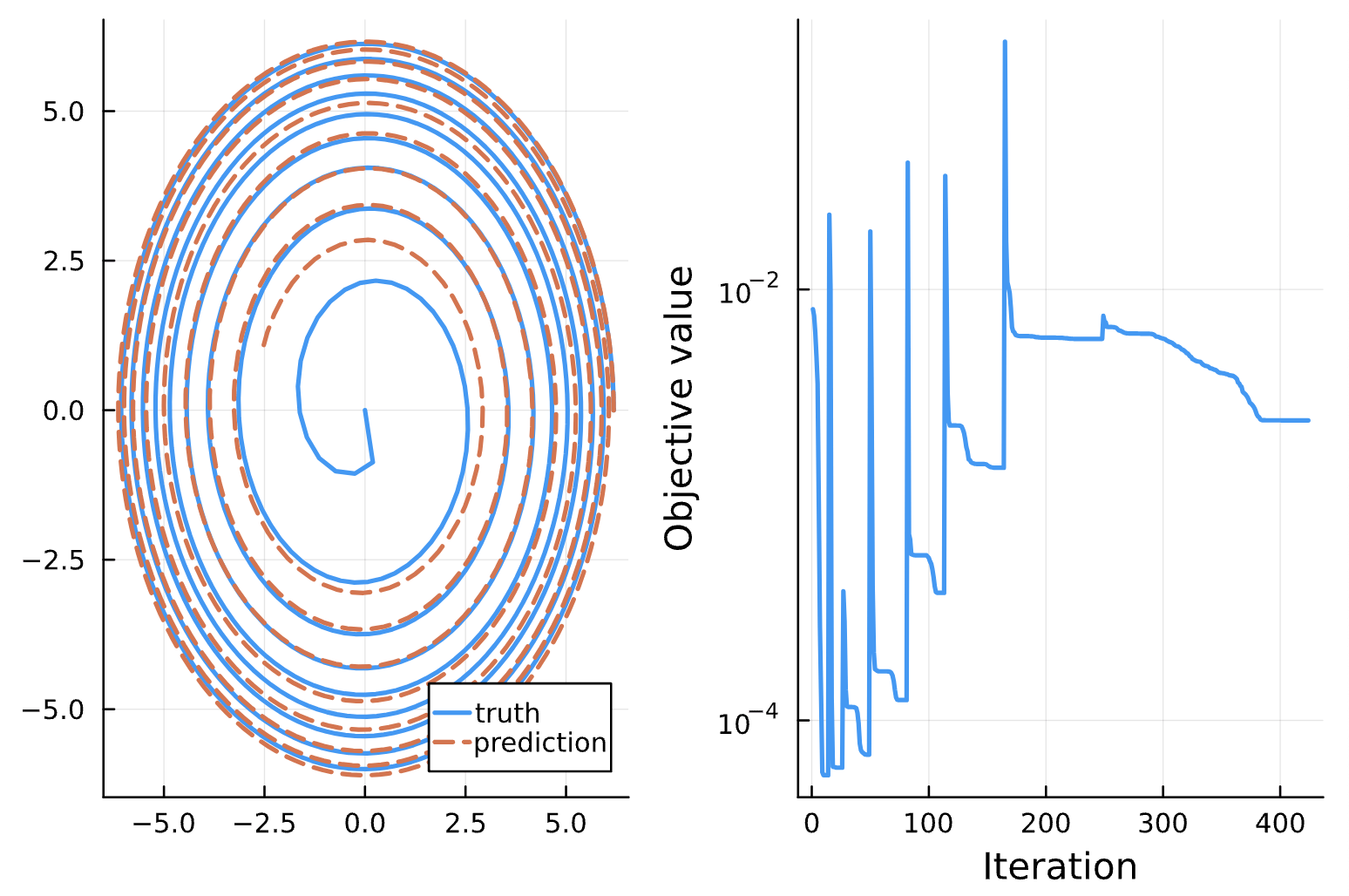
(d)
Change: Learning Rate BFGS: 0.0005 for iteration #99, 0.0001 for iteration #100
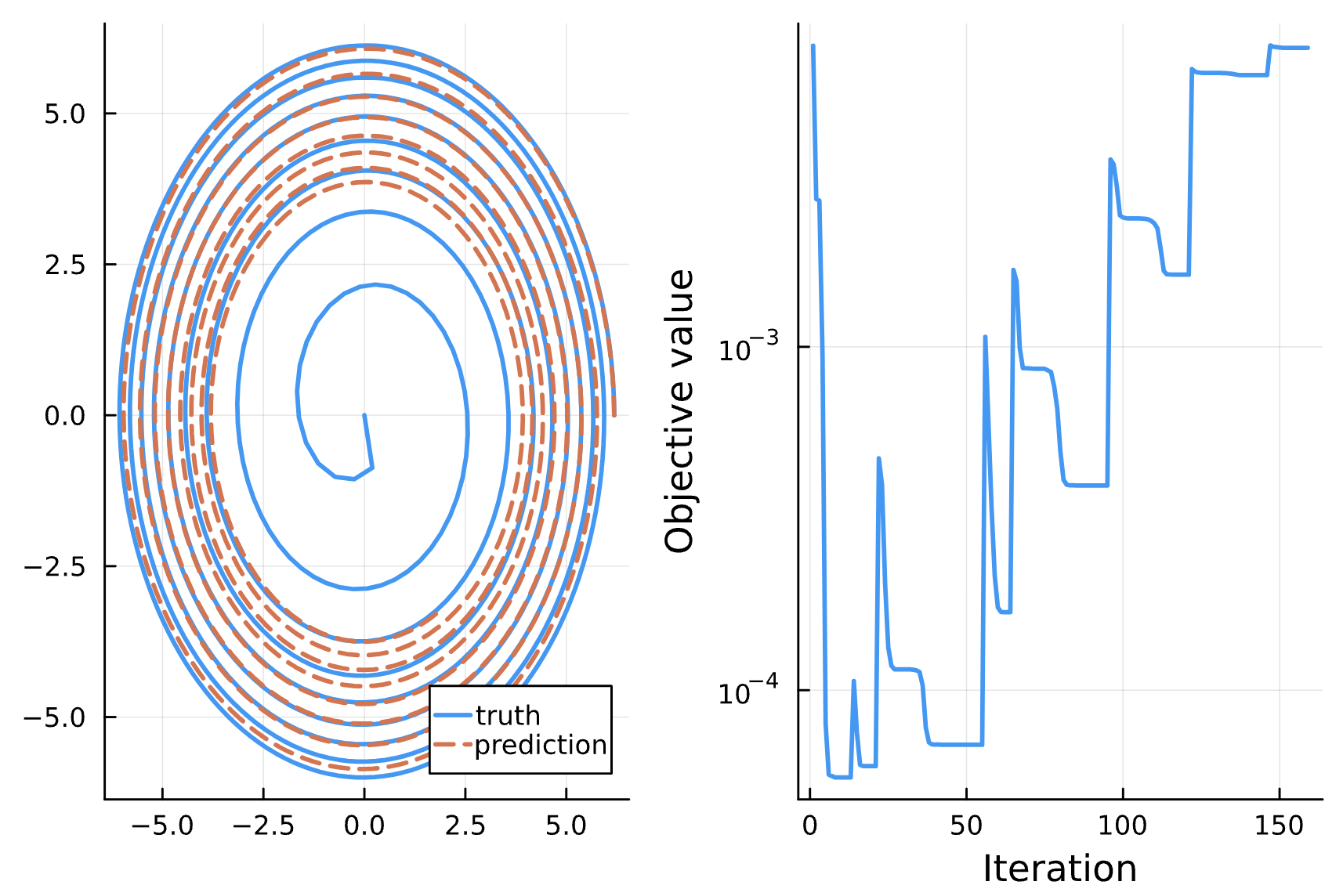
Change: Learning Rate BFGS: 0.001 for iteration #99, 5e-4 for iteration #100
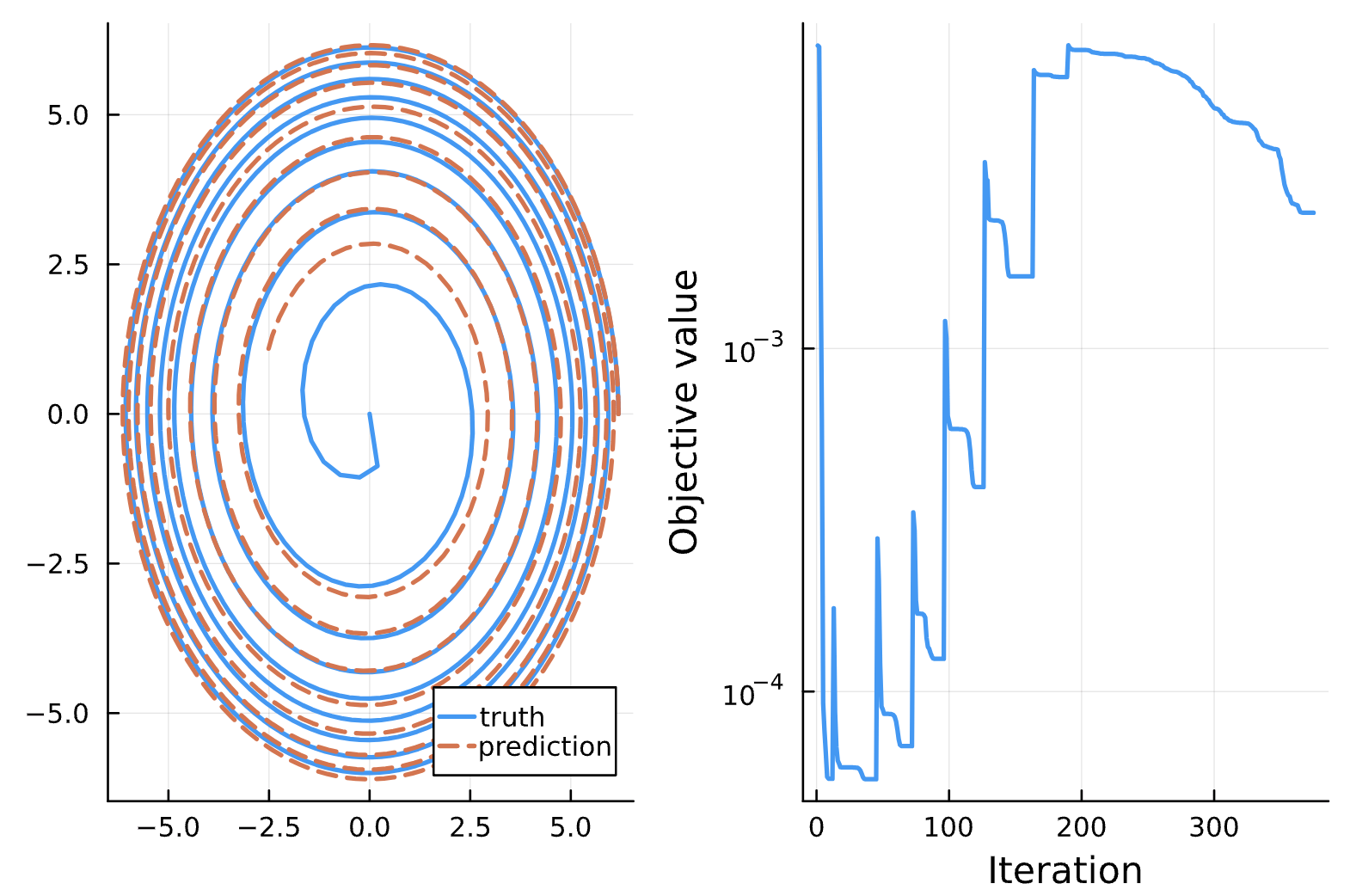
Change: Learning Rate BFGS: 0.001 for iteration #99, 5e-5 for iteration #100
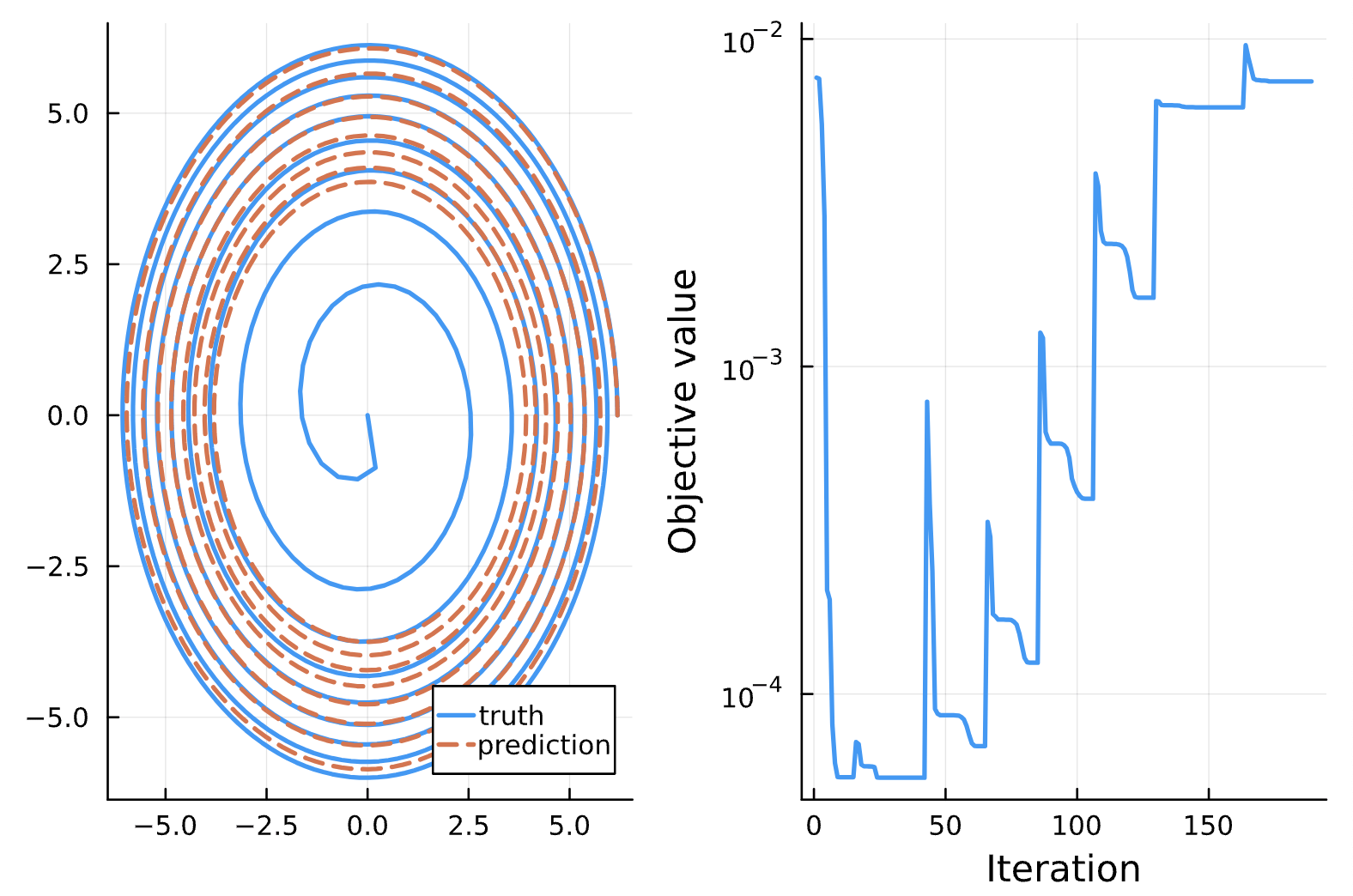
Change: dt = 5.0 (instead of 10.0)
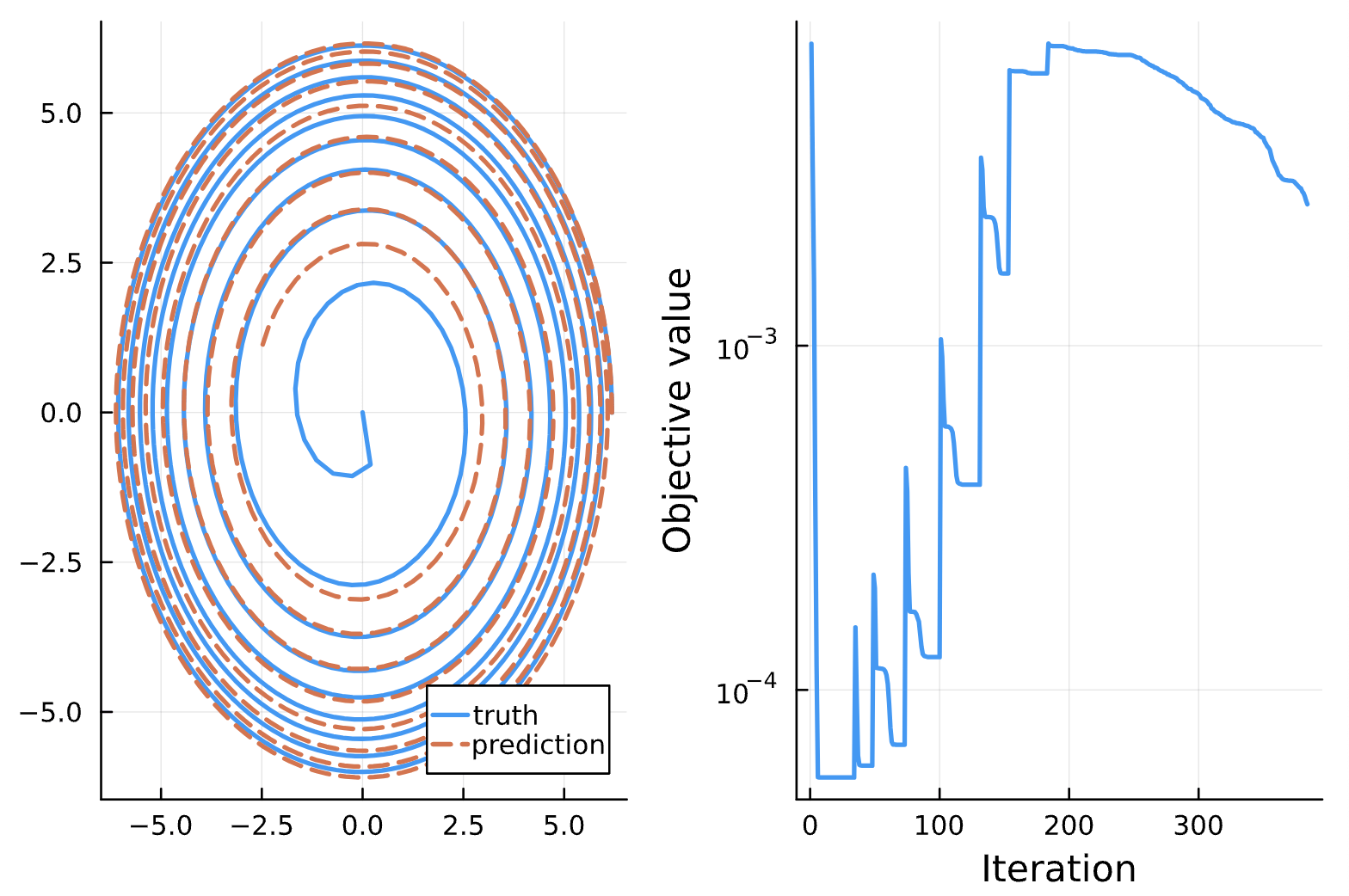
Change: maxiters = 1000 for iteration #100
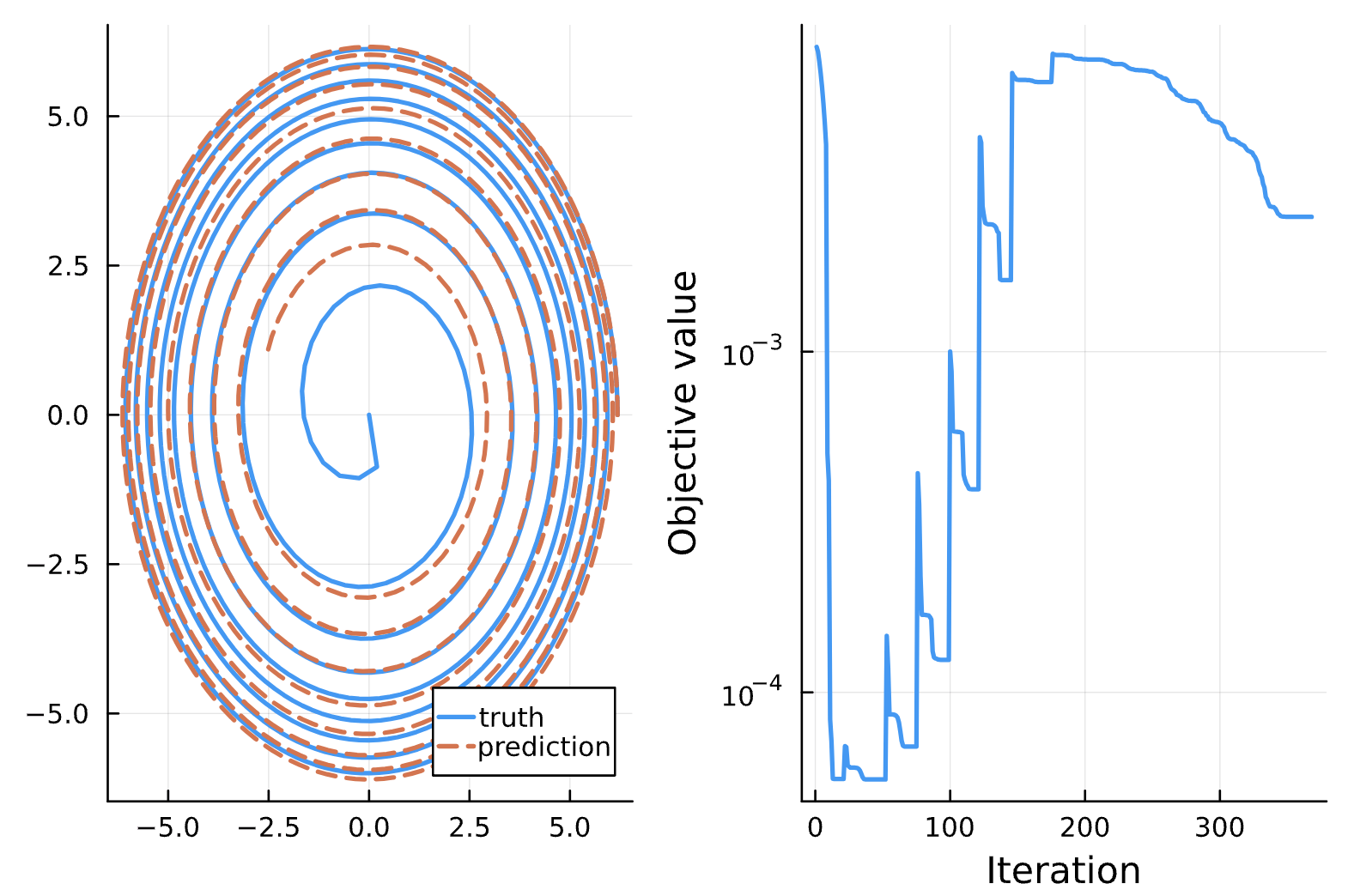
Change: 1f-3
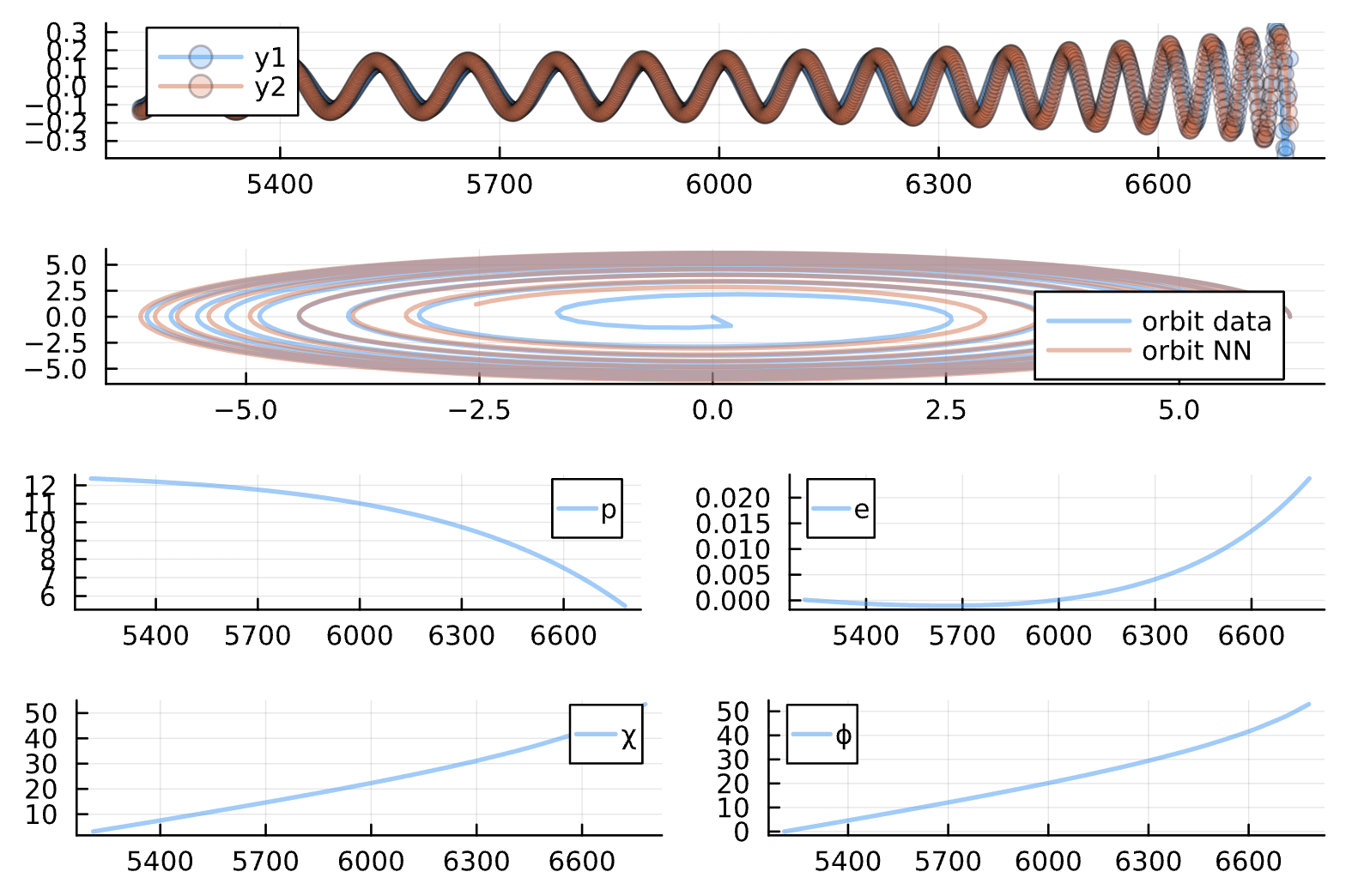
Change: last term in loss is 1f-3*sum(abs2, NN_params)
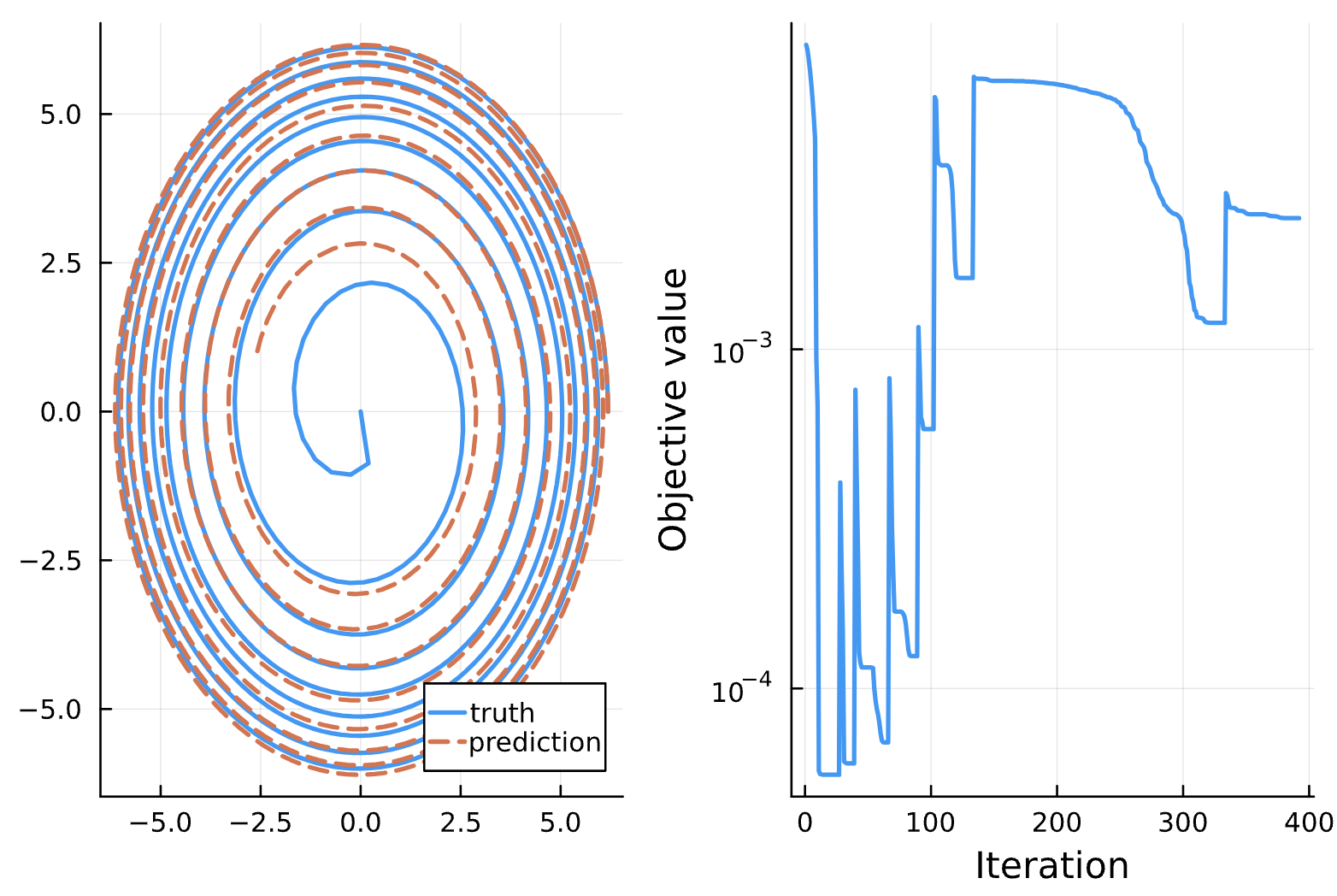
Change: last term in loss is 1f-2*sum(abs2, NN_params)
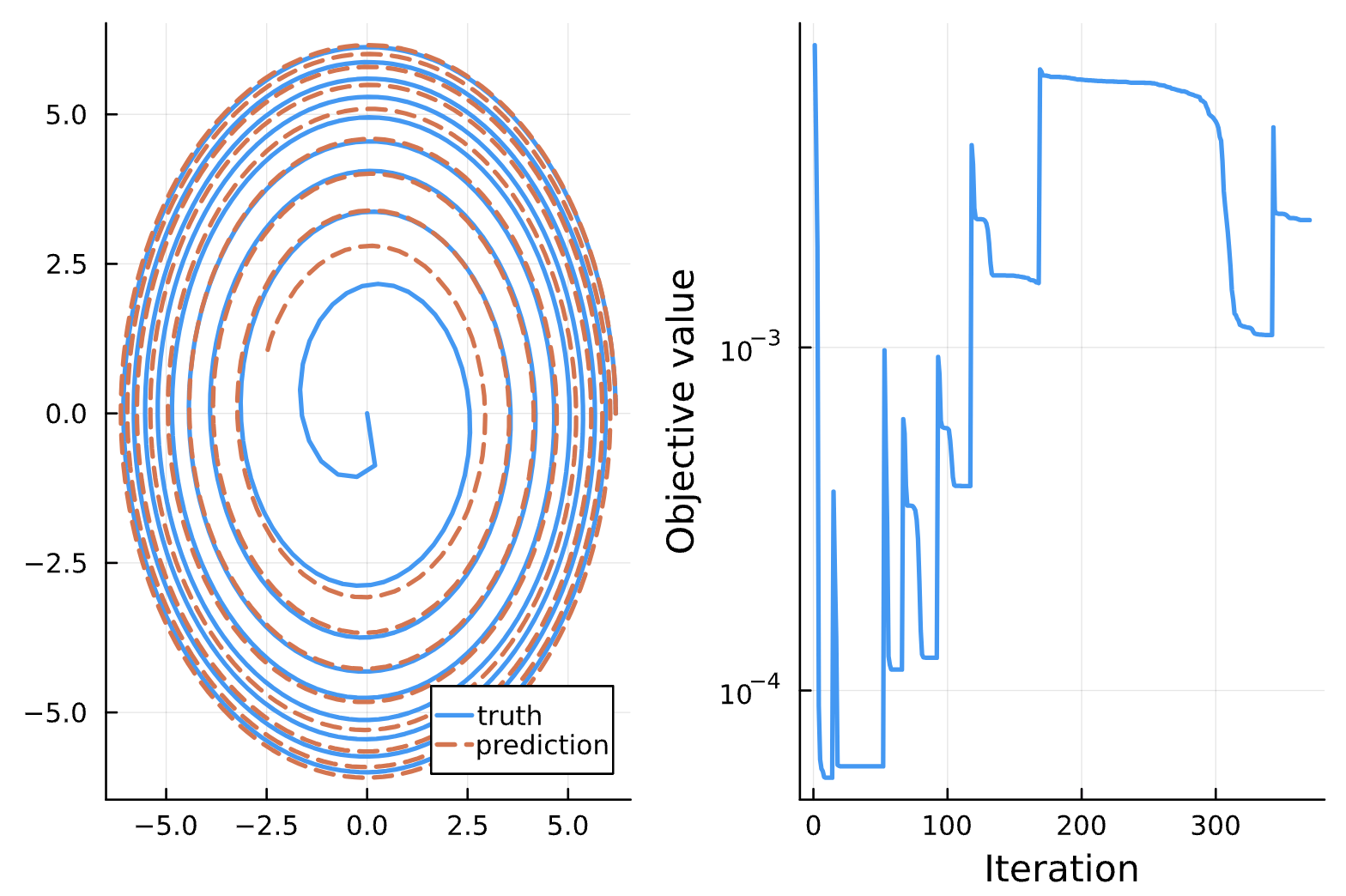
Change: 32 --> 64 nodes in each dense layer
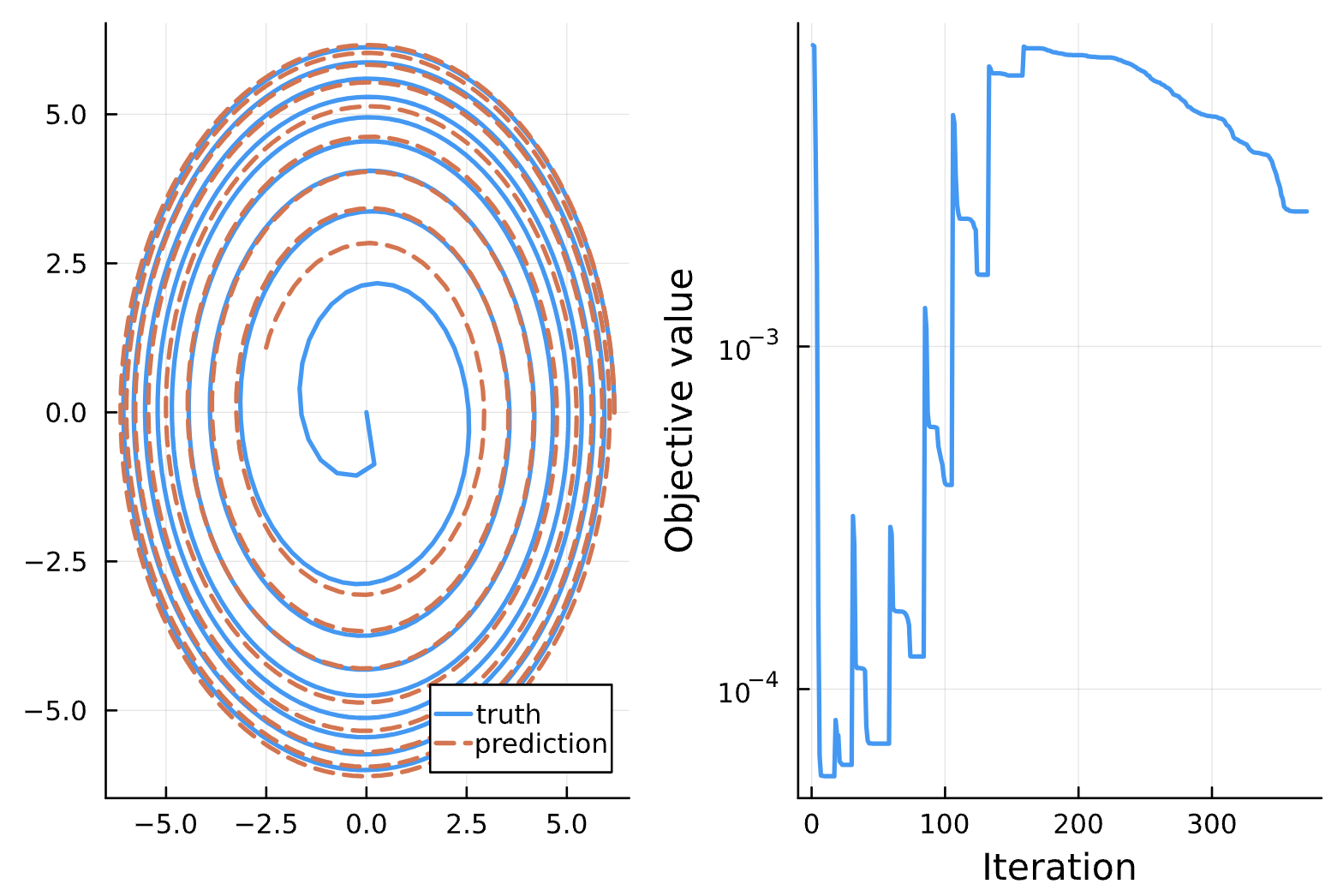
Change: Add sin(chi) and p*e anstasz to NN_chiphi
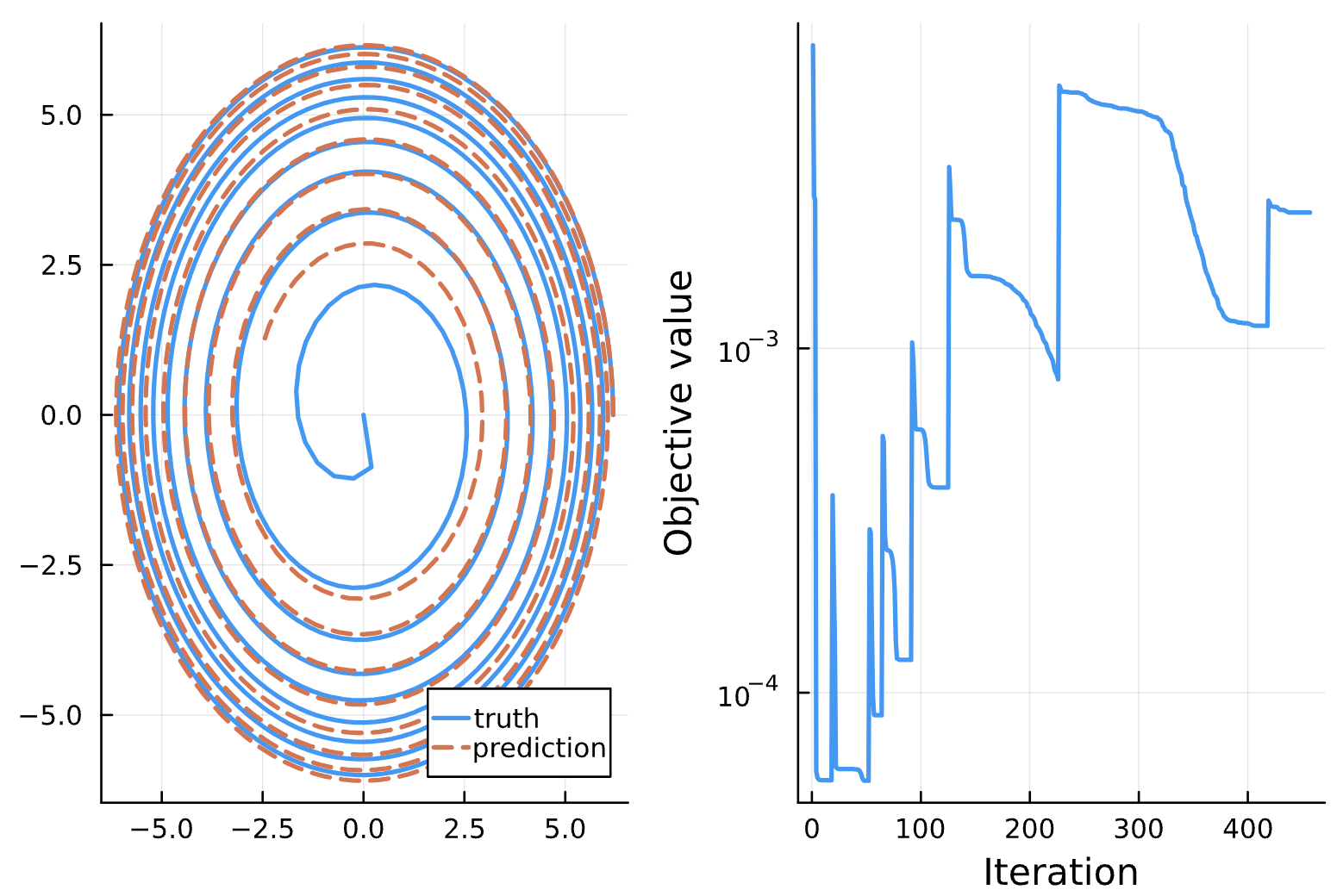
Change: num_optimization_increments = 50
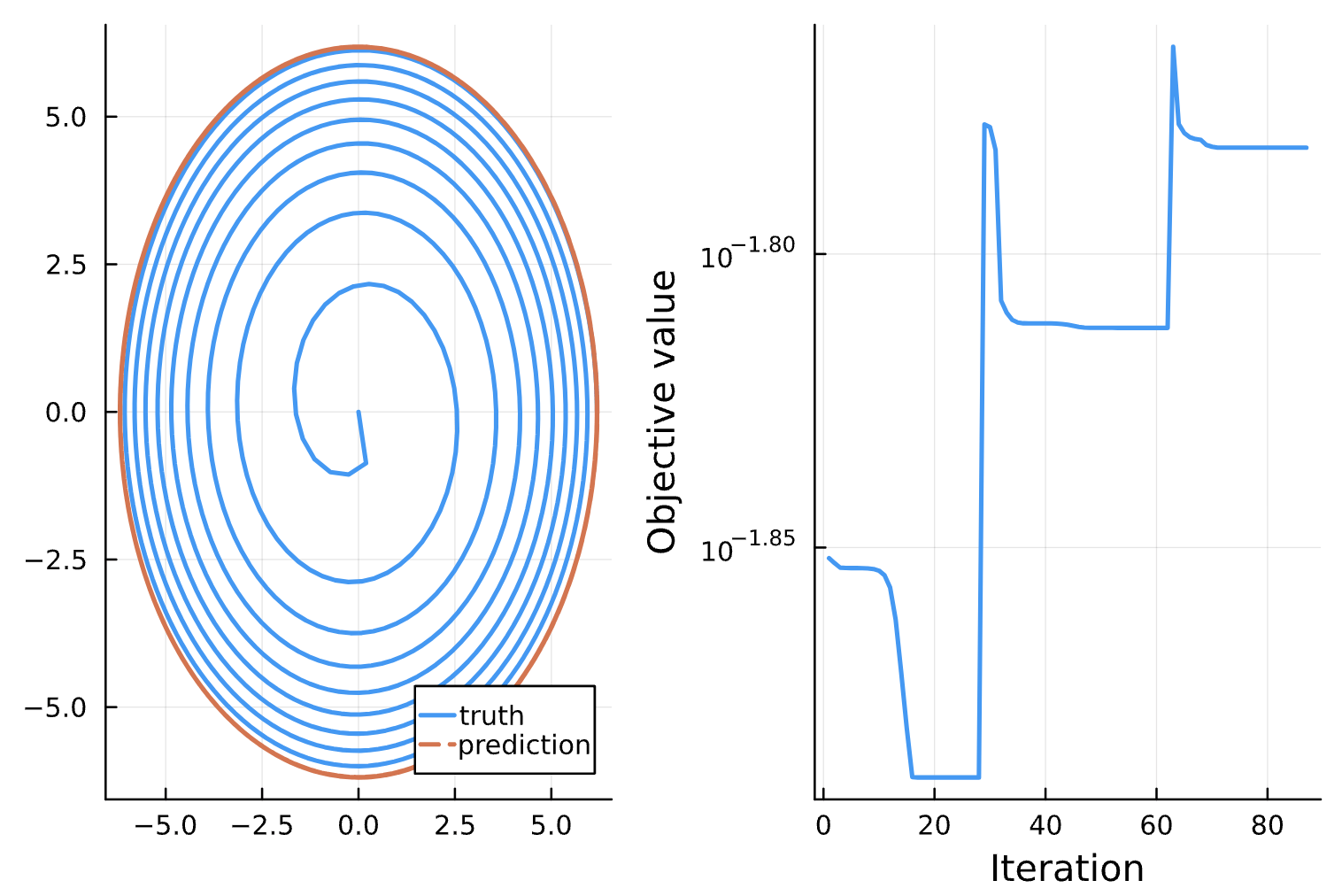
Change: number of iterations = 1000
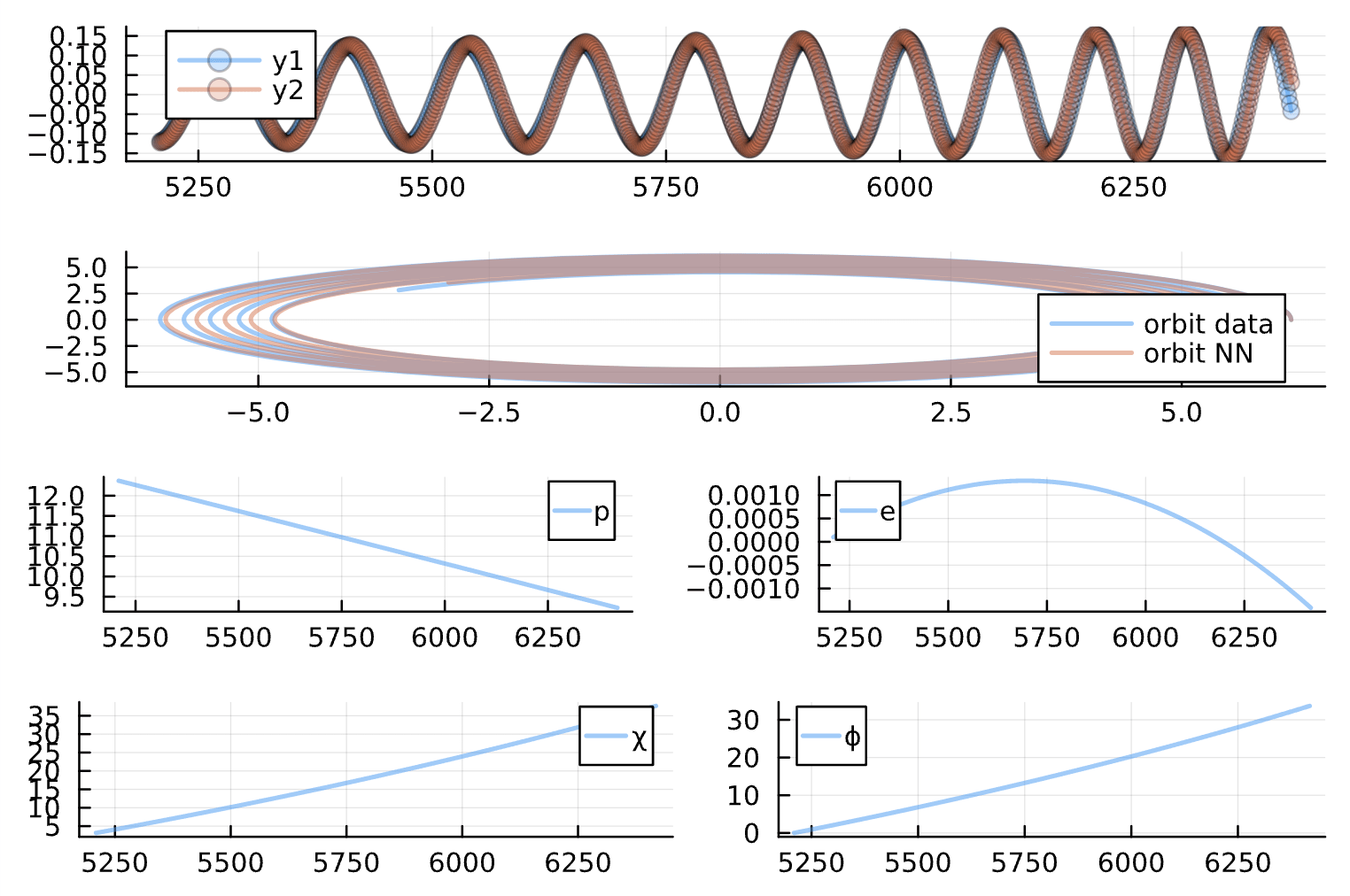
Change: Optimize iterations #97, 98, 99, and 100 with progressively smaller learning rates and greater max_iters