Module 110 - Analyser et représenter des données avec des outils
Préparer des données
partie 2
De quoi avons-nous parlé la semaine dernière ?
Temps à disposition : 5 minutes
Connectez-vous à : https://app.wooclap.com/EBFBDA

De quoi avons-nous parlé la semaine dernière ?


Démonstration des hiérarchies dans amnésia
Objectifs du cours
- Citer les critères de validation de données
- Appliquer une transformation de données
- Expliquer la méthode de l’échantillonnage

Les étapes de l'analyse de données
Nous allons voir dans les prochains slides la préparation de données, donc l'étape 2 du processus de monitoring
Lecture et validation des données
La validation des données consiste à vérifier que les informations collectées respectent certaines règles prédéfinies afin d’assurer leur qualité et leur intégrité.

Critères de validation des données
Connectez-vous à : https://app.wooclap.com/EBFBDA
et répondez à la question
Critères de validation des données
Exactitude et cohérence : Les données doivent être précises et refléter fidèlement la réalité
Exemple : Une date de naissance ne peut pas être postérieure à la date actuelle
Complétude : Une donnée est considérée comme valide si toutes les informations requises sont présentes, une absence de valeur critique peut entraîner des erreurs dans les traitements ultérieurs
Exemple: rue présente, ville manquante
Critères de validation des données
Unicité : La duplication peut entraîner des incohérences et des erreurs dans les rapports.
Exemple: Certaines données doivent être uniques comme les numéros de commande, les identifiants clients
Intégrité référentielle : Les relations entre les différentes tables ou ensembles de données doivent être respectées.
Exemple: Un utilisateur dans une table "commandes" doit exister dans la table "clients".
Critères de validation des données
Plausibilité : Certaines valeurs doivent être réalistes en fonction du contexte.
Exemple: Un salaire négatif ou une température de 500°C en Suisse sont des valeurs suspectes.
Valeurs limites
Les valeurs limites permettent de détecter les erreurs et les anomalies dans un jeu de données. Elles sont définies en fonction de la plage acceptable des valeurs pour un paramètre donné.
Types de valeurs limites :
- Valeurs minimales et maximales : Définition de bornes supérieures et inférieures
- Seuils d’alerte : Valeurs déclenchant une notification ou une correction automatique.
- Écarts-types : Identification des valeurs aberrantes à l’aide de mesures statistiques.
Valeurs limites
| Paramètre | Valeur minimale | Valeur maximale | Action si hors limite |
|---|---|---|---|
| Température serveur | 10°C | 50°C | Génération d’une alerte |
| Âge client | 18 ans | 150 ans | Vérification manuelle |
| Taux d’erreur système | 0% | 5% | Investigation si dépassement |
Liste de validation
Liste d’autorisation (Whiteliste)
Une liste d'autorisation contient des valeurs ou des ensembles de valeurs considérées comme acceptables ou sûres. Seules les données correspondant à ces valeurs sont acceptées lors de la validation.
Exemple : Dans un fichier d'analyse de données bancaire, une liste d'autorisation peut vérifier que les transactions ne proviennent que des codes des pays autorisés qu'elle contient, afin de rejeter toute transaction provenant d'un pays non répertorié.

Liste de validation
Liste de refus (Blacklist)
Une liste de refus regroupe des valeurs ou des ensembles de valeurs considérées comme indésirables ou dangereuses. Les données correspondant à ces valeurs sont rejetées lors de la validation.
Exemple : Une blacklist peut être utilisée pour bloquer les alertes inutiles en excluant certaines valeurs erronées connues, comme des capteurs défectueux qui envoient des mesures aberrantes. Cela permet d’améliorer la fiabilité des alertes et d’éviter des analyses faussées.
Transformation et nettoyage des données
Connectez-vous à : https://app.wooclap.com/EBFBDA
et répondez à la question
Transformation et nettoyage des données

Formats et types de données : Le respect des formats standards est essentiel pour assurer une compatibilité entre les systèmes et éviter les erreurs d’intégration.
Enrichissement des données : Choix, ajout ou personnalisation de colonnes
Transformation et nettoyage des données
Formats et types de données
- Formats numériques : entiers, décimaux, pourcentages.
- Formats de date et heure : YYYY-MM-DD (ISO 8601), timestamps UNIX.
- Durée : heures secondes minute
- Formats de texte : Nom, prénom, adresses avec des restrictions sur la longueur et les caractères spéciaux.
- Formats booléens : Valeurs binaires (vrai/Faux, 1/0).
Transformation et nettoyage des données
Formats et types de données
Contraintes et standardisation des formats :
- Vérification de la longueur des champs : un code postal suisse doit comporter exactement 4 chiffres.
- Formats normalisés pour garantir l’interopérabilité : adresses e-mail conformes à la norme RFC 5322.
- Conversion automatique des données mal formatées lorsqu’elles sont récupérées
Échantillonnage ou data Sampling
L'échantillonnage est une méthode statistique utilisée pour sélectionner une partie représentative d'un ensemble de données afin d'en évaluer la qualité ou d'en tirer des conclusions. En sélectionnant un échantillon représentatif, il est possible d'évaluer la qualité des données sans avoir à examiner l'ensemble de la population.
Cette méthode réduit le temps et les ressources nécessaires pour la validation, tout en fournissant des informations fiables sur l'ensemble des données
Échantillonnage ou data Sampling
Type d’échantillonnage :
- Échantillonnage aléatoire simple : Chaque élément de la population a une probabilité égale d'être sélectionnée.
- Échantillonnage stratifié : La population est divisée en sous-groupes homogènes (strates), et des échantillons sont prélevés dans chaque strate.
- Échantillonnage systématique : Les éléments sont sélectionnés à intervalles réguliers à partir d'une liste ordonnée.
Échantillonnage ou data Sampling
Type d’échantillonnage :
- Échantillonnage aléatoire simple : Chaque élément de la population a une probabilité égale d'être sélectionnée.
- Échantillonnage stratifié : La population est divisée en sous-groupes homogènes (strates), et des échantillons sont prélevés dans chaque strate.
- Échantillonnage systématique : Les éléments sont sélectionnés à intervalles réguliers à partir d'une liste ordonnée.
Échantillonnage ou data Sampling
Échantillonnage aléatoire simple
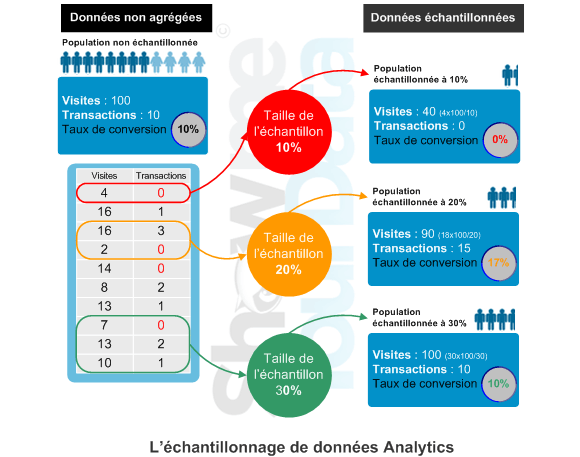
Échantillonnage ou data Sampling
Au final, on constate rapidement que des intervalles de données hétérogènes peuvent donner des résultats assez éloignés de la réalité, conclusions :
- Plus la taille de l’échantillon est grande, plus le résultat sera proche de la réalité.
- Les échantillons doivent être statistiquement représentatifs.
- La répartition des données a un impact important sur le résultat quand les sets de données ne sont pas distribués de manière homogène.
Les outils de monitoring

ELK Stack
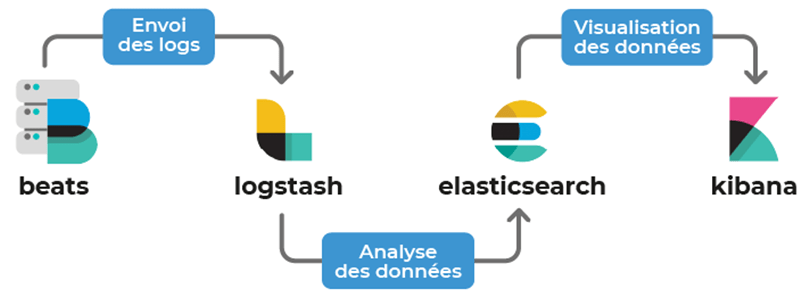
ELK Stack est un ensemble d’outils open-source composé de permettant la collecte, l’analyse et la visualisation des logs en temps réel.
ELK permet d'agréger les journaux de tous les systèmes et applications :
- De les analyser et de créer des visualisations pour la surveillance des applications et de l'infrastructure
- Permets un dépannage plus rapide
- Permets une analyse de la sécurité, etc.
ELK Stack
ELK Stack
Acronyme de Elasticsearch, Logstash et Kibana. Représente trois outils open source créé et maintenu par Elastic souvent appelée Elasticsearch :
- Elasticsearch: est un moteur de recherche et d'analyse distribuée. Il est conçu pour indexer, rechercher et analyser rapidement de grandes quantités de données structurées et non structurées en quasi-temps réel.
- Logstash : permets la collecte, transformation et la distribution de données.
- Kibana : Est un tableau de bord. Il est utilisé pour la visualisation et la création de tableaux de bord
ELK Stack
ELK Stack
Beats est un ensemble d’outils permettant l’envoi de logs. Ces outils devront être installés sur les machines qui seront monitorées. Ils agiront comme des agents qui collectent les journaux d'événement et logs :
-
Filebeat : ingestion de fichiers de logs
-
Packetbeat : ingestion de fichiers de capture réseau
-
Auditbeat : ingestion de fichiers audit
-
Heartbeat : vérification si un service est disponible ou non
-
Functionbeat : monitoring des environnements cloud
-
Journalbeat : ingestion des logs systeme
-
Metricbeat : collection des métriques de différents systèmes
-
Winlogbeat : collection de logs Windows
ELK Stack
ELK Stack
Logstash permet l'agrégation et le formatage de données pour l’envoi dans Elasticsearch. Logstash vous permettra donc d'envoyer différents types de données autres que des logs.
ELK Stack
ELK Stack
ElasticSearch est le moteur principal de la stack ELK : c’est lui qui va stocker les données et les rendre accessibles.
ELK Stack
ELK Stack
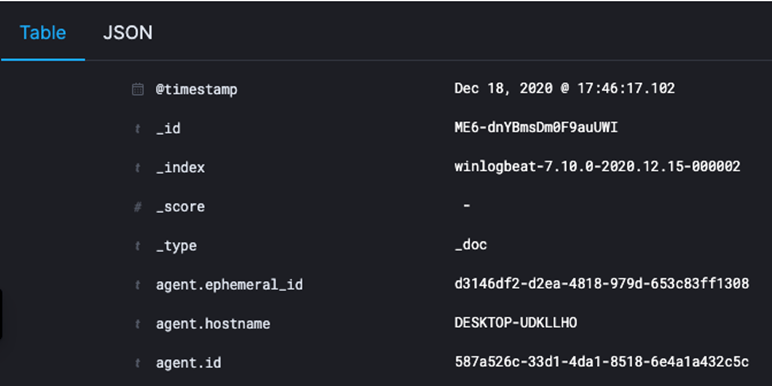
Elasticsearch stocke les données au format JSON. Ces données sont contenues dans des index qui sont des bases de données.
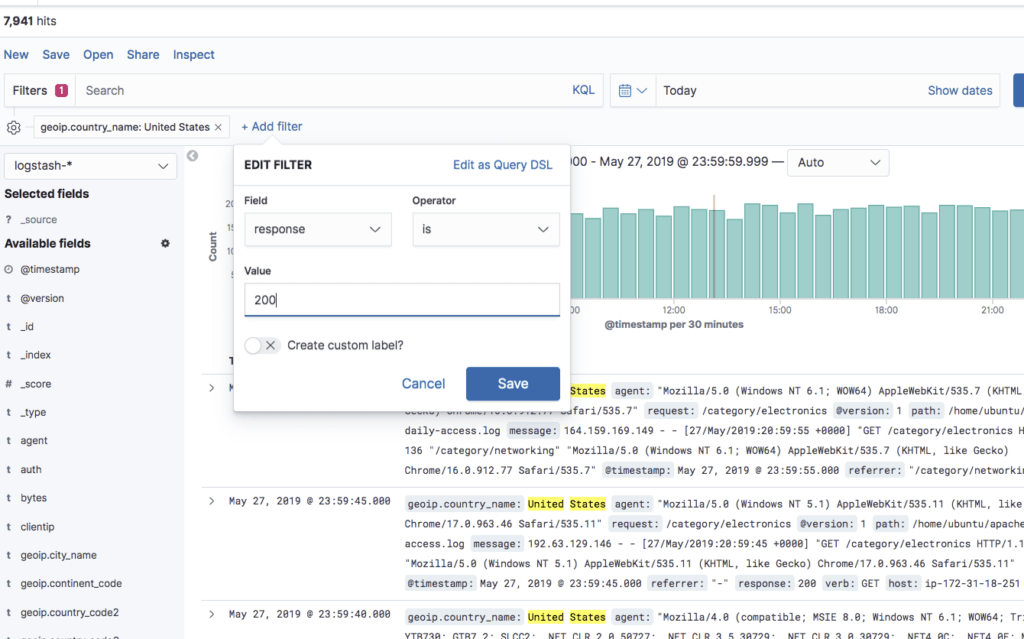
Les index contiennent des documents dans lesquels les données sont organisées dans des “fields”, c'est-à-dire des champs. Dans le screenshot ci-dessous, des fields sont définis dans la colonne de gauche
Pour récupérer les données,
Elasticsearch fonctionne
comme une API RESTful
ELK Stack
ELK Stack
Elasticsearch stocke les données au format JSON. Ces données sont contenues dans des index qui sont des bases de données.
Les index contiennent des documents dans lesquels les données sont organisées dans des “fields”, c'est-à-dire des champs. Dans le screenshot ci-dessous, des fields sont définis dans la colonne de gauche
Pour récupérer les données,
Elasticsearch fonctionne
comme une API RESTful
ELK Stack
ELK Stack
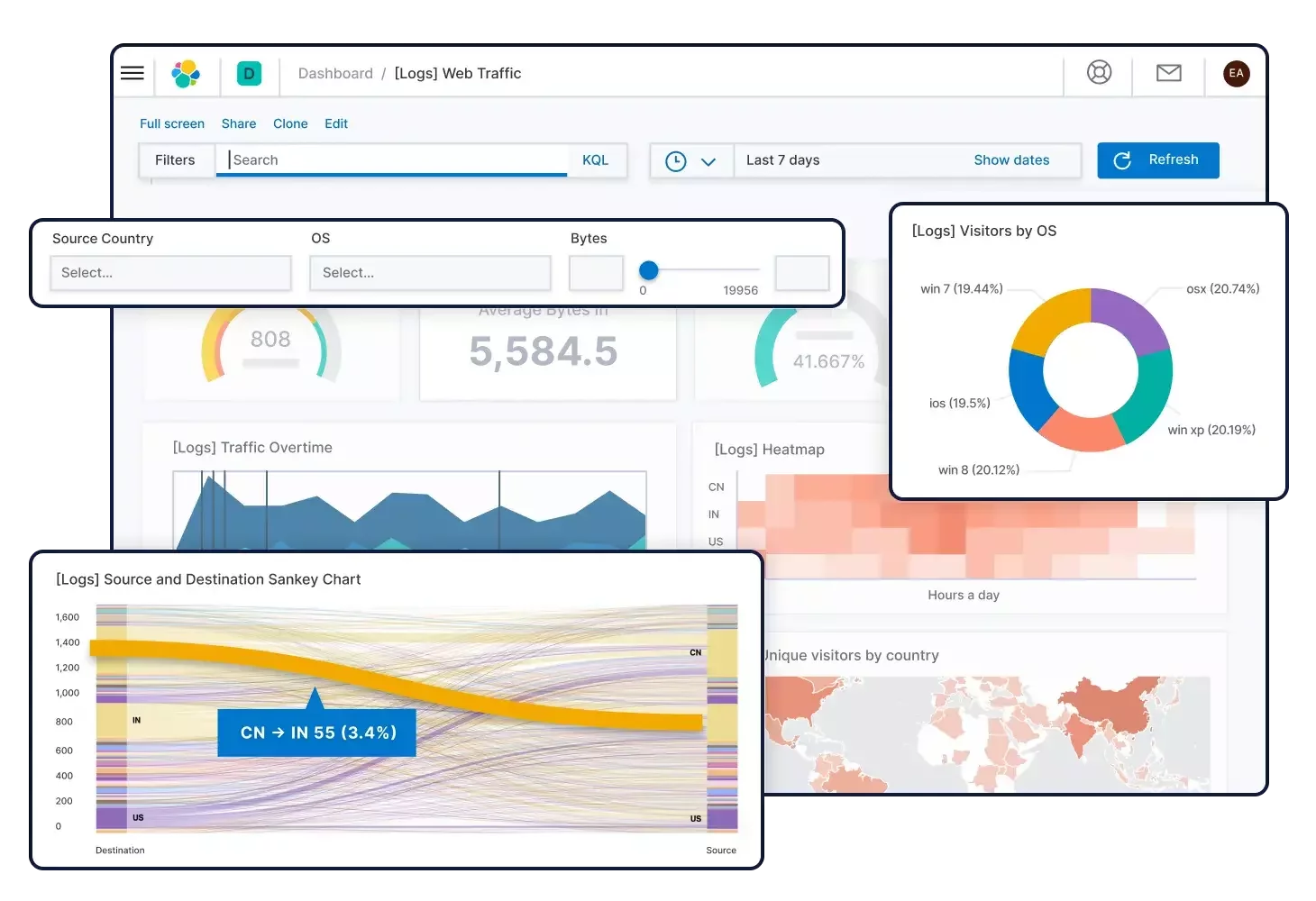
Kibana va permettre de visualiser les données d’Elasticsearch en temps réel. Cet outil vous propose des dashboards préconfigurés pour analyser les logs qui vous sont remontés. Il est également possible de visualiser et d'explorer vos données dans la section Discover
Splunk
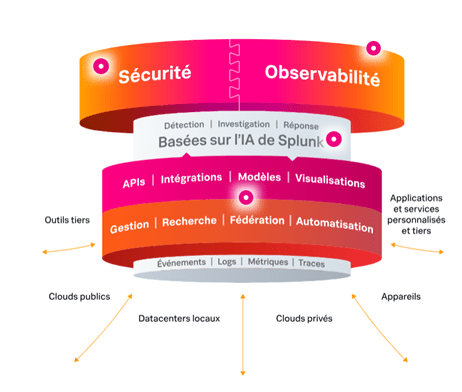
Splunk est une plateforme propriétaire spécialisée dans la collecte, l’indexation et l’analyse des données issues des logs en temps réel. Elle permet d'effectuer des recherches avancées, de créer des alertes et de générer des tableaux de bord interactifs.
Splunk
En plus d'être une plateforme de gestion et d'analyse des journaux, Splunk est également commercialisée comme une solution de gestion des informations et des événements de sécurité SIEM
(Security Information and Event Management)
- Connue sous le nom du « Google pour les fichiers journaux » SIEM est simplement une gestion des journaux appliquée à la sécurité
- Le portail Splunk App propose plus de 1 000 modules complémentaires et applications
Autres outils
Graylog
est une solution de gestion des journaux (log management) et d'analyse de données en temps réel. Il est souvent utilisé pour centraliser, analyser et visualiser les logs des systèmes et applications.
Cas d'utilisation :

- Surveillance de la sécurité des systèmes
- Détection des anomalies dans les logs
- Analyse des performances d'applications
- Débogage des erreurs d'applications
Autres outils
Autres outils
Wazuh
est une plateforme de sécurité open-source orientée SIEM (Security Information and Event Management). Elle se concentre sur la surveillance de la sécurité, la détection des menaces, et la conformité.
Cas d'utilisation :
- Surveillance en temps réel des systèmes et réseaux contre les intrusions
- Gestion des vulnérabilités pour identifier les failles de sécurité
- Analyse des incidents de sécurité
- Conformité avec les réglementations de sécurité

ELK Stack dans Docker
Cas pratique

Effectuez le Cas pratique 5 - Transformer et nettoyer les données dans ELK
Temps: 45 minutes

Wooflash
Répondez aux différentes questions liées à la matière enseignée
Connectez-vous à : https://app.wooflash.com/join/1G69UJX7
110-3 Préparer des données - partie 2
By Myriam Fallet



