Conception
d'une IA de jeu vidéo avec
l'apprentissage par renforcement
Vincent Ogloblinsky - @vogloblinsky
Vincent Ogloblinsky
Compodoc maintainer


Architecte logiciel web
Indie hacker on side-projects


Agenda
1.
L'IA dans les jeux vidéos/recherche
2.
Apprentissage par renforcement
3.
L'architecture actor-critic
4.
L'implémentation & défis rencontrés
5.
Démos
6.
Bilan
L'IA
dans les
jeux vidéos / recherche

L'IA dans les jeux vidéos / recherche

PACMAN - 1980
Premiers patterns fixes d'IA pour les 3 fantômes
Illusion d'intelligence et de personnalité distincte

L'IA dans les jeux vidéos / recherche
DOOM - 1993
Des ennemis réactifs et stratégiques, simulant une intelligence pour rendre chaque affrontement imprévisible.

L'IA dans les jeux vidéos / recherche

LES SIMS - 2000
Une IA basée sur des besoins et émotions qui donne l'illusion d'une personnalité autonome.
L'IA dans les jeux vidéos / recherche
CIVILIZATION VI - 2010
L'IA utilise des stratégies adaptatives et des comportements complexes pour simuler des leaders humains crédibles et imprévisibles.

L'IA dans les jeux vidéos / recherche
DEEP BLUE - 1997
L'IA utilise une recherche exhaustive et des heuristiques pour simuler une intelligence stratégique dans la partie d’échecs.

L'IA dans les jeux vidéos / recherche
AlphaGo - 2016
Combine l'apprentissage par renforcement et les réseaux neuronaux pour simuler une intuition stratégique et imprévisible dans le jeu de go.
L'IA dans les jeux vidéos / recherche
AlphaStart - 2019
Utilise l'apprentissage par renforcement et la simulation pour adopter des stratégies complexes et adaptatives dans StarCraft II.
Apprentissage par renforcement

Apprentissage par renforcement - What
Personne ne lui explique les lois de la physique
Il essaie, tombe, se rétablit, et apprend de l'expérience
Il reçoit un signal simple : ça marche / ça ne marche pas
Un enfant qui apprend à faire du vélo
Apprentissage par renforcement - What
L'IA explore son environnement sans connaitre les règles

Elle teste différentes actions
Elle reçoit des récompenses (positives ou négatives) après chaque action
Elle s'améliore en maximisant les récompenses
Apprentissage par renforcement - Why
❌ Pas de dataset d'entraînement existant
❌ Règles complexes difficiles à programmer
❌ Actions continues (pas de boutons ↑ ↓ A B)
✅ L'IA doit apprendre par l'expérience



Apprentissage par renforcement - Where

3 types de jeu :
- local (solo vs IA)
- multijoueur local
- multijoueur online
2 modes de jeu : classique ou cible
Apprentissage par renforcement - Where


Mode cible : Viser des zones de score sur la planche
Actions continues (force, direction, rotation)
Apprentissage par renforcement - Where
Physique complexe avec collisions
6 palets par joueur, premier à 30 gagne
Actions discrètes (classiques) :
Choix parmi un ensemble fini : ↑ ↓ A B
Exemples : déplacements sur grille, boutons de manette
Apprentissage par renforcement - Where
Actions continues (notre défi) :
Valeurs dans un intervalle infini : force ∈ [1, 6]
Exemples : angle de tir, intensité, rotation précise
Gameplay simple à complexe
Mode cible : maximiser les points individuels
Apprentissage par renforcement - Where
Mode classique : placer ses palets près du "maître"
L'architecture actor-critic

Architecture actor-critic
2 familles d'apprentissage par renforcement :
Policy-based : apprendre directement la stratégie optimale, c'est-à-dire apprendre la meilleure façon de jouer dans chaque situation
Value-based : apprendre combien chaque coup rapporte et choisir le meilleur coup
De l'hybride avec les 2 existe aussi
Architecture actor-critic
Trois cerveaux qui collaborent
Actor : décide de l'action à prendre - quel geste faire
Critic : évalue la qualité de la décision - était-ce une bonne idée ?
Observer : avant de décider quoi faire, il observe la situation de jeu
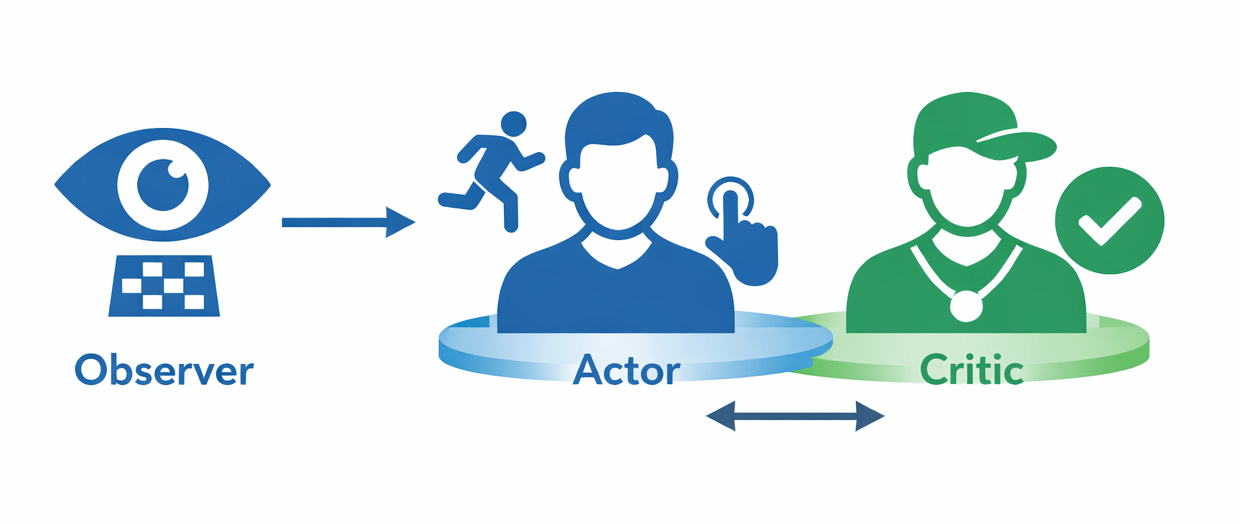
Architecture actor-critic
Réseau de neurones : système informatique inspiré du cerveau humain, composé de plusieurs couches de petits éléments appelés neurones
Neurones : reçoivent des données, les traitent/transforment, puis en transmettant le résultat aux neurones suivants, etc, pour finalement produire une réponse ou une décision.

Architecture actor-critic - avantages
Réduit la variance (instabilité)
Le Critic évalue chaque action individuellement, plutôt que de se fier uniquement au résultat final — comme un cuisinier qui note chaque plat séparément, pas seulement l'avis global des invités en fin de repas
Sans Critic, on n'apprendrait qu'une chose : "la partie était gagnée ou perdue" — impossible de savoir quel lancer précis était bon ou mauvais
Meilleure exploration (algorithme interne qui encourage l'actor à ne pas converger trop vite)
Implémentation et défis rencontrés

Implémentation - Stack technique
Mode de jeu "cible"
Playwright pilote un vrai navigateur → le jeu tourne en entier (rendu 3D Babylon.js + physique Rapier)
L'IA injecte ses actions et récupère l'état du jeu via des hooks sur "window"
Bilan : ~3 épisodes par minute — trop lent pour le mode adversarial
Avec moins d'entrées sur le modèle, et moins en sortie
Implémentation - Stack technique
Mode de jeu "classique"
Rapier (le moteur physique) tourne directement en Node.js, sans navigateur, sans 3D, sans rendu
Des workers en parallèle simulent des parties simultanément (IA & adversaire)
TensorFlow.js entraîne le réseau dans le thread principal à partir de leurs résultats
Bilan : ~1 000 épisodes par minute — ~333 fois plus rapide
Implémentation - Stack technique
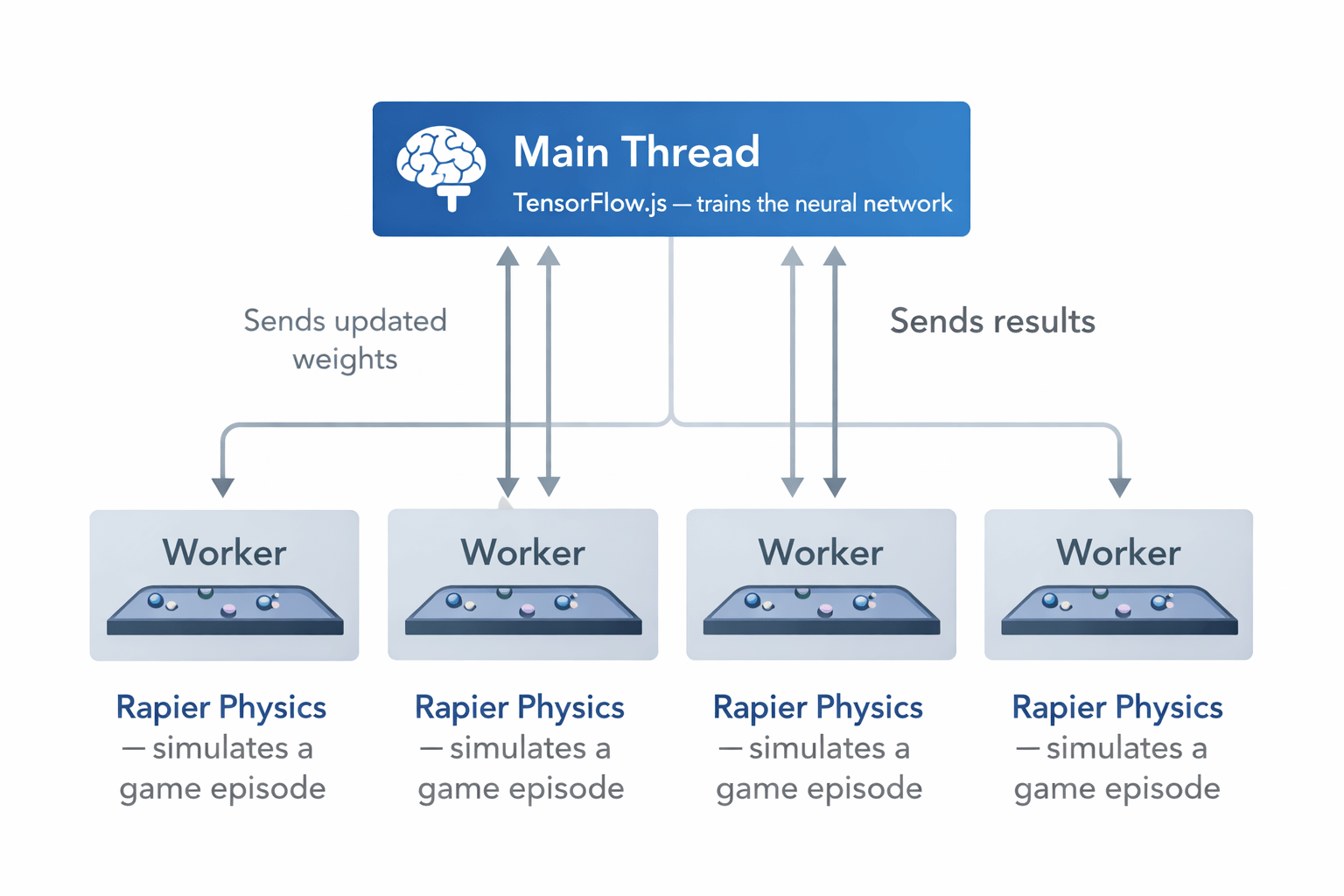
Macbook Pro M4 Pro
8 workers Node.js
256 parties réparties sur les 8 workers
Learn, clear, repeat : 1172 fois
4h au total pour 300 000 parties
1h45 pour 300 parties du mode cible
Implémentation
Cycle d'apprentissage :
1. Le thread principal envoie les poids courants aux 8 workers
2. Chaque worker simule des parties complètes (Actor choisit les actions)
3. Les workers renvoient leurs résultats (états, actions, récompenses)
4. Le thread principal accumule jusqu'à 256 épisodes collectés, le Critic les évalue
5. Le thread principal met à jour Actor + Critic
6. On jette tout le buffer (les actions + analyse des 256 parties)
7. "Même joueur joue encore" 🔄
Implémentation - Comment lui dire ce qui est bien
IA classique (rules-based) — on programme des comportements :
si palet_adverse_proche_du_maître → essayer de le pousser
si ma_position_est_bonne → jouer défensif
Le développeur a décidé de la stratégie.
Reinforcement learning — on programme un objectif :
si mon_palet_proche_du_maître → récompense positive
si palet_adverse_proche_du_maître → récompense négative
L'IA découvre elle-même que pousser peut être une bonne idée. On n'a jamais dit "attaque". Elle l'a inféré.
Implémentation - Comment lui dire ce qui est bien
Implémentation - apprendre contre un adversaire qui évolue
1 worker = une partie de l'IA contre un adversaire : elle-même, quelle version ?
- si l'adversaire change trop vite, l'IA ne peut pas apprendre
- si l'adversaire ne change pas, l'IA exploite ses failles sans progresser vraiment
Solution : Liga
1 : adversaire qui joue au hasard → l'IA apprend à lancer correctement
2 : mélange aléatoire / ancienne version de l'IA conservée dans un pool de "fantômes"
3 : self-play contre une version gelée récente
Implémentation - apprendre contre un adversaire qui évolue
3 approches successives
1ère : le décideur apprend uniquement de ses parties les plus récentes, et oublie le reste dès qu'il en fait de nouvelles
→ Simple, efficace en solo.
Mais contre un adversaire qui change, il "oublie" trop vite ce qu'il a appris.
2ème : on ajoute un carnet de match — toutes les parties passées sont stockées, et le décideur peut réapprendre depuis n'importe quelle ancienne transition
→ Stable en théorie.
En pratique : le carnet accumule aussi les mauvaises habitudes prises contre de vieux adversaires dépassés.
Implémentation - apprendre contre un adversaire qui évolue
Problème pas anticipé : le self-play peut empoisonner l'entraînement
Chambre d'écho du self-play.
Un joueur s'entraine contre lui-même : si un service gagne 60% du temps
Son adversaire (lui-même) s'y adapte de la même façon.
Les deux ne sont bons qu'à ça, et nuls face à toute autre situation.
Implémentation - apprendre contre un adversaire qui évolue
3 approches successives
3ème : retour à "apprendre de ce qui vient de se passer", mais avec un mécanisme plus malin.
Après chaque cycle de collecte, les données sont jetées.
Aucune transition ne peut polluer l'entraînement.
→ Nouveau défi : sans accumulation, l'IA risque de converger trop vite vers une seule stratégie.
Contre-poids ?
Une IA "basique"
Implémentation - apprendre contre un adversaire qui évolue
IA "basique" - codée à la main avec des règles et des heuristiques
Une machine à états : si je mène, je défends ; si l'adversaire est mieux placé, j'attaque
Pour le placement du maître : tirage aléatoire parmi 25 positions disponibles pré-calculées, mémorisées pour toute la manche
Résultat : un adversaire qui ne joue jamais deux fois pareil, mais qui applique toujours une logique lisible
Pour les lancers : viser le palet adverse le plus proche du maître, ou poser le sien près du maître selon la situation
Implémentation - apprendre contre un adversaire qui évolue
IA "basique" - heuristiques des lancers
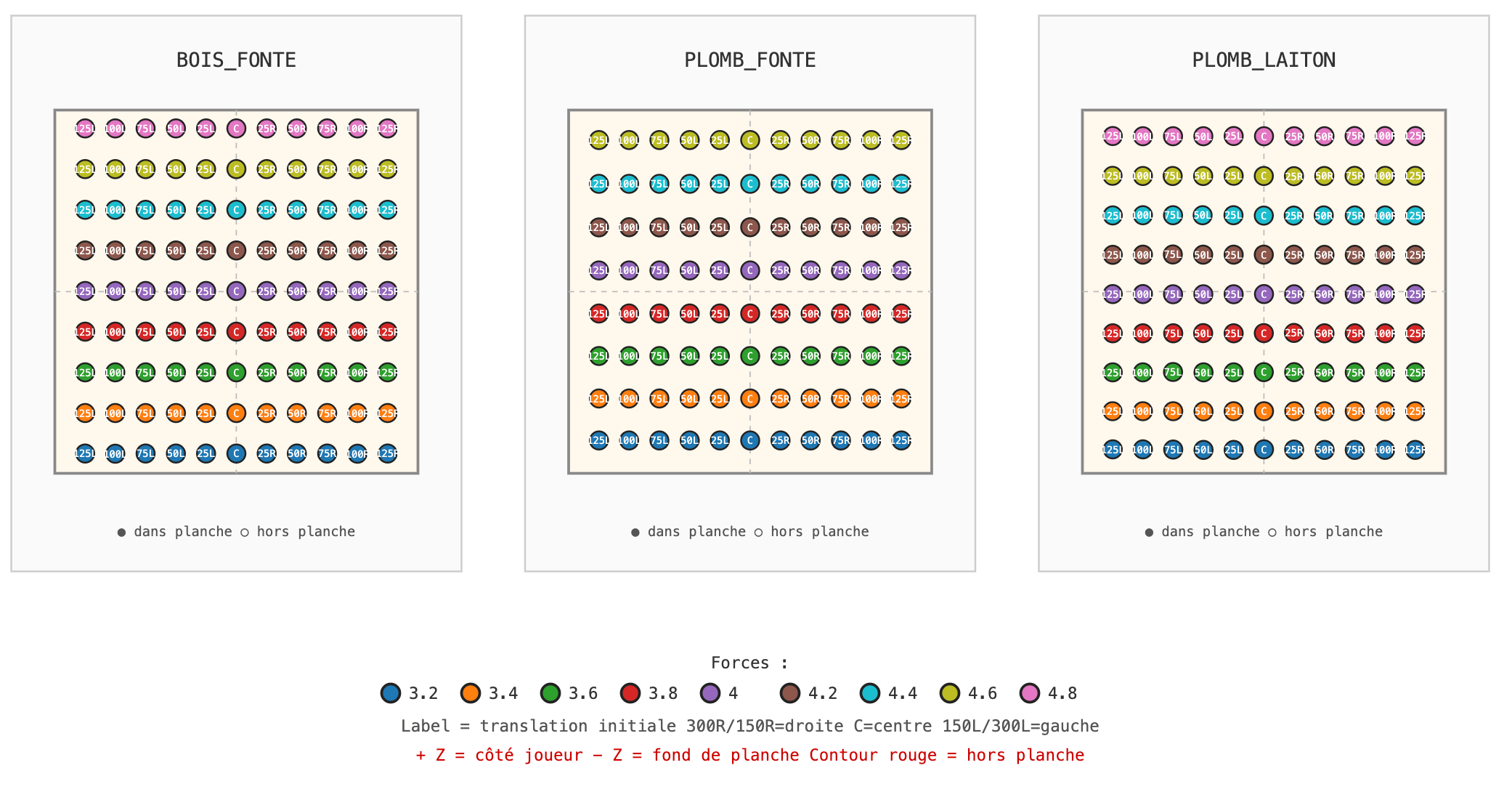
Implémentation - Modèle de l'IA
115 entrées
2 couches cachées
Actor
52 sorties
~92k paramètres

Critic
1 sortie
Implémentation - Modèle de l'IA
Entrées : état du jeu encodé sur 115 dimensions :
- type de planche
- type de palet
- rôle, position, score et status de chaque palet
- phase de jeu (maître ou palet)
- qui mène
2 couches cachées :
- Couche 1 : 256 neurones
- Couche 2 : 256 neurones
7 sorties spécialisées pour les actions continues :
- rotation (direction et intensité)
- translation (direction et intensité)
- force du lancer
- inclinaison du palet (2 axes)
🎮 Le réseau Actor (le joueur)
~92k paramètres
Implémentation - Modèle de l'IA
Contexte global
Type de palet actuel
Type de planche
Position du maître (x, z — normalisée + valeur absolue)
Phase de jeu
Bonus palets restants
Tentatives de placement du maître
Passes de placement
Qui mène
Par palet × 10 (IA : 1 MAIN + 4 NORMAL, adversaire : idem)
Rôle
Status
Position (x, y, z)
Orientation (x, y, z)
Distance au maître
Est le plus proche
Entrées
Queue stratégique
Position du maître (x, z) — répétée
Score IA
Score adversaire
Implémentation et défis rencontrés

Entrées
Implémentation - Modèle de l'IA
Couche 1 : 256 neurones
détecte des patterns simples
"le maître est à gauche", "je suis derrière"
Couche 2 : 256 neurones
combine ces patterns en concepts plus abstraits
"je suis derrière ET le maître est loin ET l'adversaire est proche
→ situation critique"
Implémentation et défis rencontrés
Reward
Implémentation - Modèle de l'IA
🎮 Le réseau Actor (le joueur)
Avec 115 dimensions d'entrée, l'espace des états est relativement complexe :
Sous-dimensionnement (ex: 32-64 neurones) → Risque de sous-apprentissage
Sur-dimensionnement (ex: 512-1024 neurones) → Risque de surapprentissage
PPO (Proximal Policy Optimization) : souvent 64-256 neurones
A3C (Actor-Critic) : typiquement 128-512 neurones
DDPG : architectures similaires 256-128 neurones
Bon compromis entre capacité d'apprentissage et efficacité computationnelle pour un jeu avec actions continues.
Implémentation - Modèle de l'IA
7 sorties spécialisées pour les actions continues :
🎮 Le réseau Actor (le joueur)

- rotation (direction et valeur)
- translation (direction et valeur)
- force du lancer + diagonale
- inclinaison du palet (2 axes)
Implémentation - Modèle de l'IA
🧠 Le réseau Critic (le coach)
1 sortie :
Évalue la qualité d'un état donné pour guider l'apprentissage de l'Actor.
Total : ~67k paramètres
110 entrées
3 couches cachées
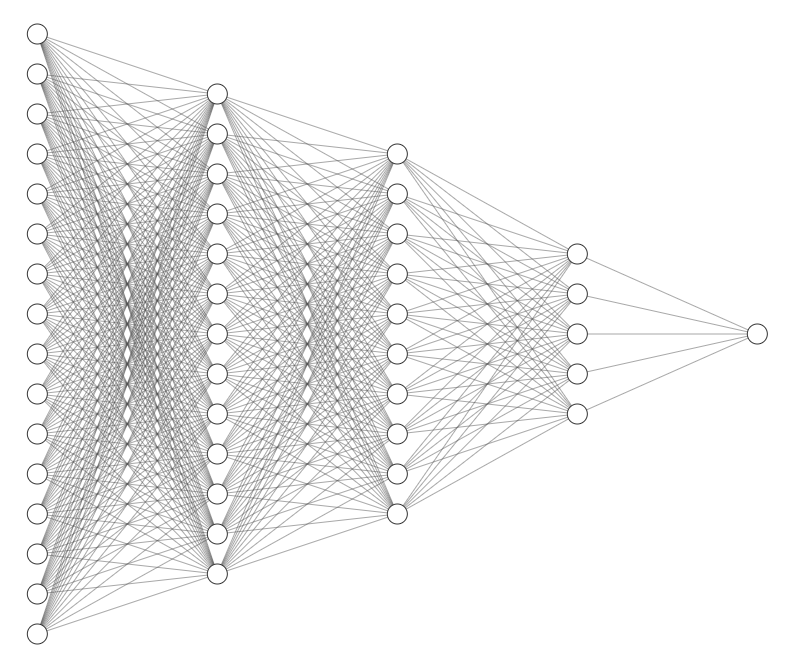
Implémentation - Modèle de l'IA
Babylon.js (3D)
Rapier.js (Physique)
Jeu
TypeScript
Playwright
contrôle navigateur
Tensorflow.js
IA Actor-critic
Hooks mis à disposition pour la couche supérieure via objet global window
- récupération état du jeu
- pilotage des actions (lancer, rotation etc)
Script global pilotant Playwright et Tensorflow.js
Implémentation et défis rencontrés
export interface GameState {
mode: string;
players: Player[];
type: string;
planche: Planche;
}export type PlancheType = 'BOIS' | 'PLOMB';
export interface Planche {
type: PlancheType;
position: Position;
}export interface Player {
palets: Palet[];
}export type PaletType = 'FONTE' | 'LAITON';
export type PaletStatus = 'ALANCER' | 'VALID' | 'INVALID';
export type PaletRole = 'MAIN' | 'NORMAL';
export interface Palet {
type: PaletType;
role: PaletRole;
status: PaletStatus;
position: Position;
score: number;
}Implémentation et défis rencontrés
Obstacles
🎯 Actions continues
- Plus complexe que des actions discrètes
- Espace d'exploration immense
⚖️ Équilibrage exploration/exploitation
- Trop d'exploration → surapprentissage (incapable de s'adapter à des situations nouvelles)
- Pas assez → stratégies sous-optimales
🎲 Non-déterminisme physique
- Collisions entre palets imprévisibles
- Même action ≠ même résultat
Implémentation et défis rencontrés
Solutions
🎯 Normalisation des actions (entrée/sorties du réseau neuronal vers les vraies valeurs du jeu (degrés, vitesse, distance)
rotation: -1 à 1 → 0 à 200
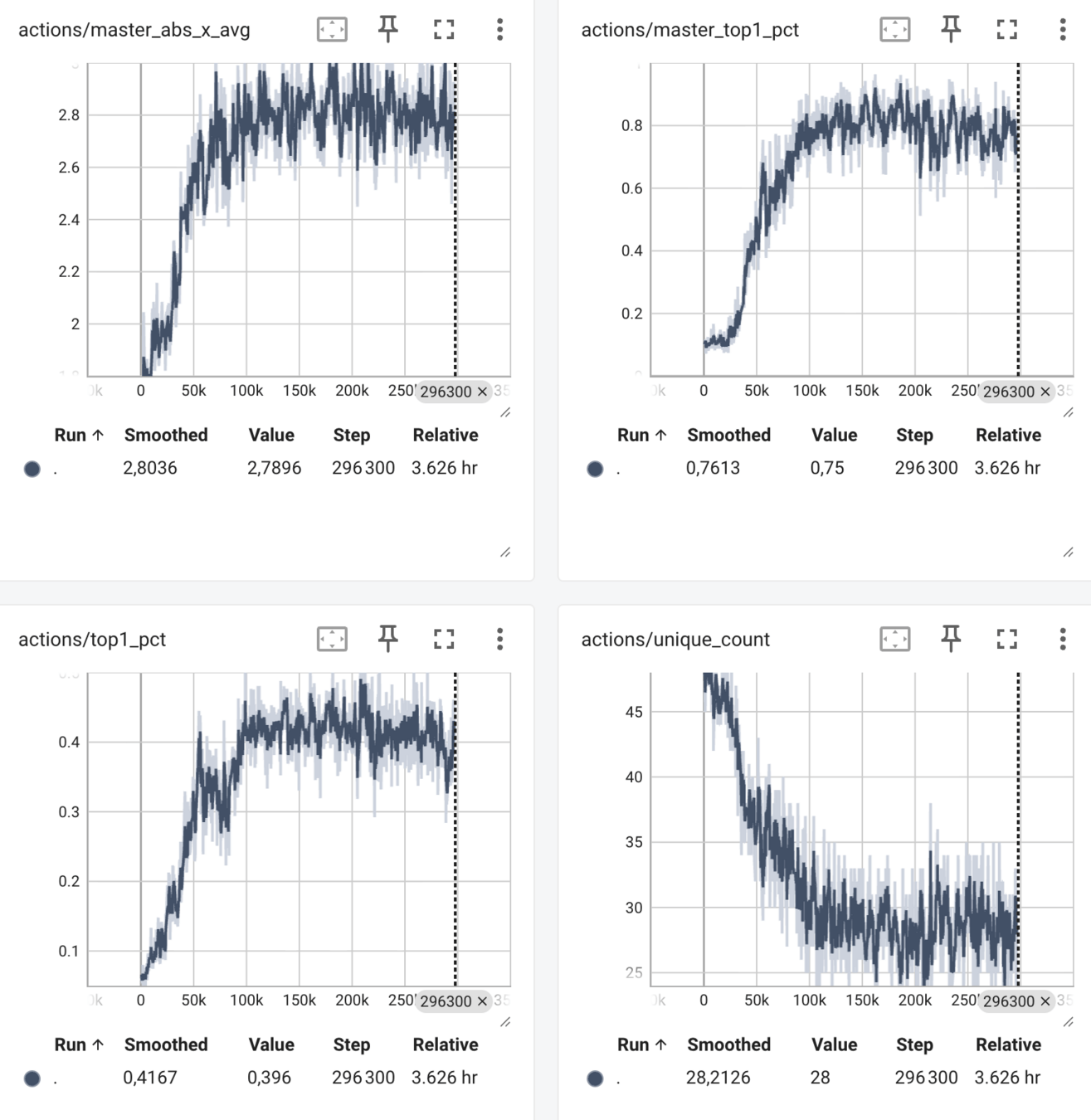
📊 Métriques détaillées
- Logs JSON + TensorBoard
- Suivi épisode par épisode et lancer par lancer
🔄 Entraînement progressif
- Checkpoints réguliers
- Sauvegarde/rechargement des modèles
Implémentation et défis rencontrés
Niveaux finaux de l'IA
Checkpoints toutes les 10 000 épisodes pendant l'entrainement
On prend simplement 3 checkpoints :
- forte : checkpoint 150 000
- très forte : checkpoint 250 000
- experte : checkpoint 300 000
Implémentation et défis rencontrés
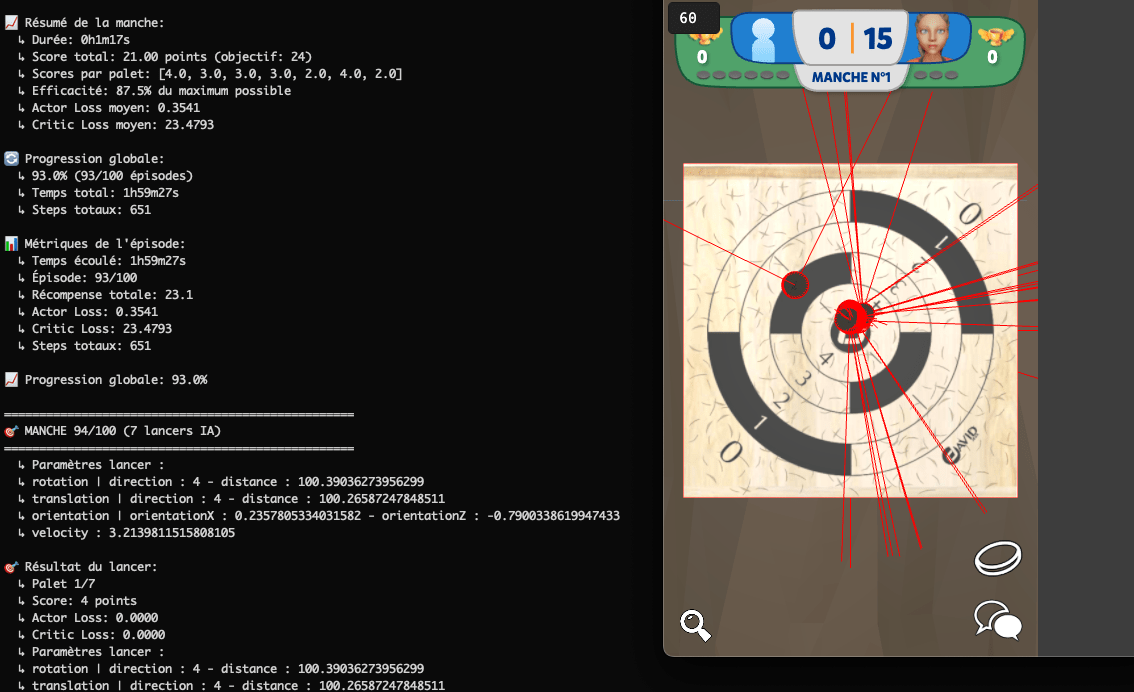
Démos


Bilan

Bilan
On n'a pas codé une seule règle de stratégie — on a codé ce qui vaut des points
La complexité est dans la reward, pas dans des if/else
Les comportements émergent d'eux-mêmes
Mais : l'IA optimise ce qu'on lui demande, pas ce qu'on veut
Ce qu'on lui demande = la reward function — la formule exacte qu'on a codée, avec ses mots choisis, ses coefficients, ses cas qu'on n'a pas anticipé
Ce qu'on veut = ce qu'on avait en tête quand on l'a écrite — un adversaire imprévisible, varié, intéressant à affronter
La reward est une approximation de ce qu'on veut. L'IA optimise la formule à la lettre — et elle trouve les failles de l'approximation.
Conseils
Keep It Simple Stupid - Bon sens paysan - Pragmatic Driven Development
Commencer simple, complexifier progressivement
Garder un adversaire externe (règles codées, humain, oracle) pour briser les boucles de self-play
Tester en conditions réelles régulièrement — pas seulement regarder les courbes
Sauvegarder souvent — un entraînement plante, c'est du temps perdu
Prototyper et valider votre idée/gameplay "le plus tôt possible"
Ne pas hésiter à changer d'approche si ça ne converge pas — mais anticiper que la nouvelle approche aura ses propres pièges
Ressources
Ressources
Série Rematch
Merci pour votre attention !
Des questions ?
Slides : https://bit.ly/42ZSJ01
Crédit photos - Unsplash.com
Beta publique : https://bit.ly/palet-jeu-video-beta
Conception d'une IA de jeu vidéo avec l'apprentissage par renforcement
By Vincent Ogloblinsky
Conception d'une IA de jeu vidéo avec l'apprentissage par renforcement
Programmez un objectif, pas des règles." C'est la promesse de l'apprentissage par renforcement. Vous définissez ce qui vaut des points, l'IA trouve toute seule comment en marquer. Pendant plusieurs mois, j'ai mis cette promesse à l'épreuve sur un jeu de palet fonte/laiton sur planche bois/plomb, en entraînant une IA à jouer contre un adversaire humain — sans lui coder une seule règle de stratégie. Dans ce talk, je vous raconte le vrai parcours : - Comment une IA apprend, avec 3 cerveaux qui collaborent - Les 3 approches que j'ai enchaînées — chacune résolvant le problème de la précédente, chacune en créant un nouveau - Le "piège de l'imitation de soi-même" : quand une IA qui s'entraîne contre elle-même finit par ne plus jouer qu'un seul coup Avec du vrai code, des démos live, et un message qui dépasse le jeu vidéo : l'IA optimise ce qu'on lui demande, pas ce qu'on veut. Pour les développeurs curieux d'explorer l'IA dans les jeux vidéo, avec démos concrètes et conseils pratiques pour lancer vos propres projets RL.



