
\text{Introduction to Generative AI}
\textbf{Naresh Kumar Devulapally}
\text{CSE 4/573: Computer Vision and Image Processing}
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Lecture 12: July 10, 2025}
\text{in Computer Vision}
CVIP 2.0
\text{Intro to GenAI: Data Distribution}
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}

- Recap of Discriminator models (Neural Networks for function approximation).
- Deep NNs and CNNs.
- Low-Dimensional features in CNNs.
- Where does data come from?
- What is the structure of a data? What is a distribution?
- Types of distributions
- Approximating a distribution
- Why Gaussian Distribution is ubiquitous?
- Bayes rule and Marginalization
- Images as data points
- Interpolation for data generation
\( \text{Agenda of this Lecture:}\)
\text{July 10, 2025}
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Function Approximators. (Recap)}
y = f(x)
(1, 2)
(1.5, 3)
(-0.5, -1)
Let's say you are given a bunch of data points:
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Function Approximators. (Recap)}
y = f(x)
(1, 2)
(1.5, 3)
(-0.5, -1)
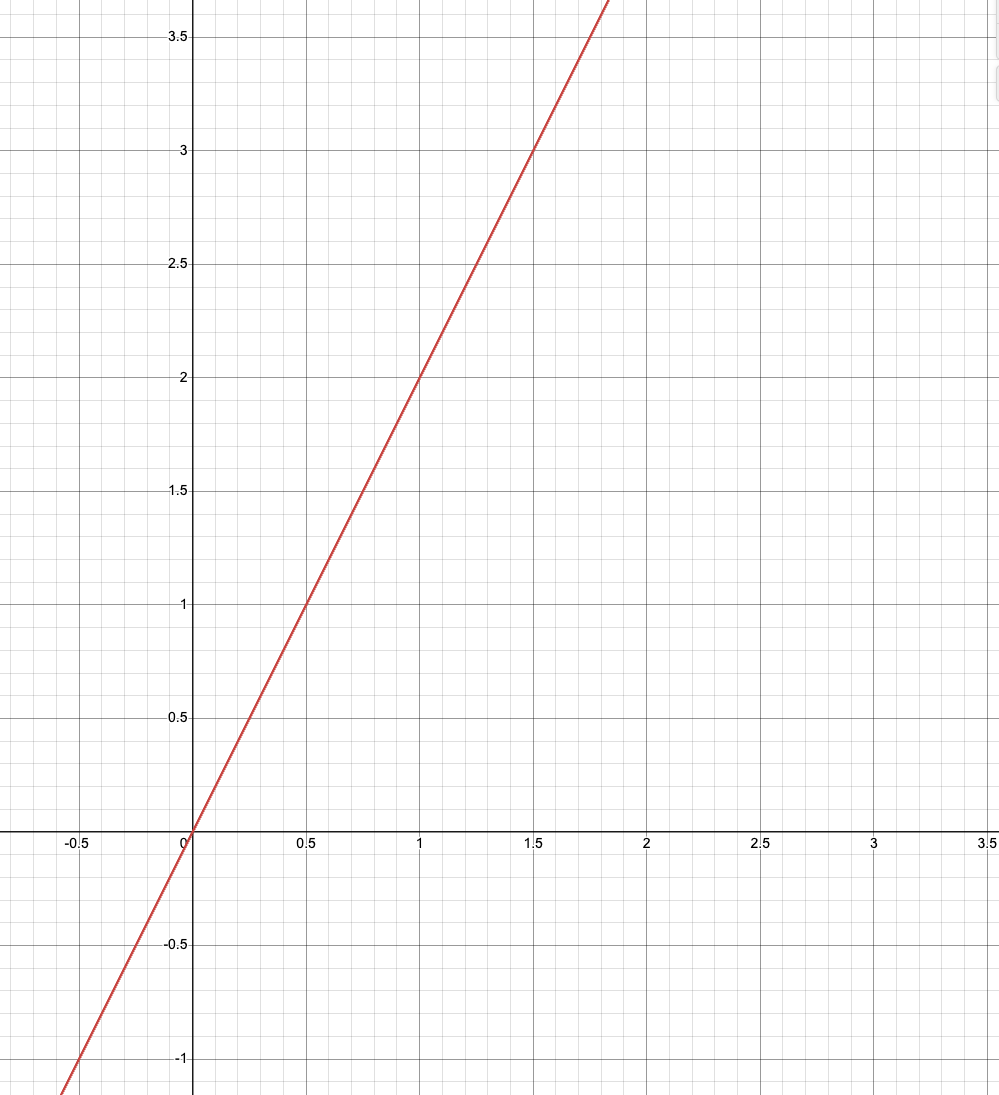
?
(0.5, ?)
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Function Approximators. (Recap)}
\text{Neural Networks}
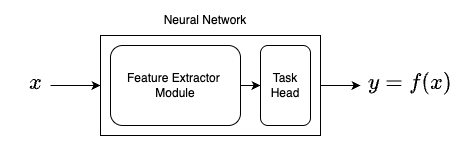
Neural Networks have two components:
- Feature Extractor Module
- Task specific head
You can experiment with simple neural networks at Tensorflow Playground
Usually extracted features are of
lower dimension than data (x)
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Function Approximators. (Recap)}
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Function Approximators. (Recap)}
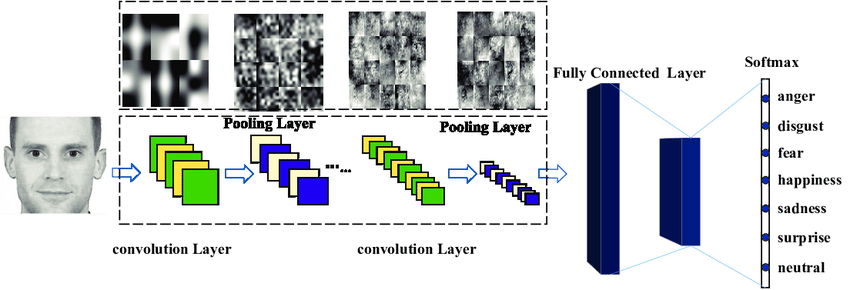
A simple example of a Neural Network
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Function Approximators. (Recap)}
\text{Discriminative v/s Generative models}
y = f(x)
We have very powerful discriminator models:
- E.g., Image classification models
x = f^{-1}(y)
What about generative models?
Given a label (e.g., "cat"), can we
generate a data point (image)?
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
x
y
1
2
3
4
5
6
1
2
3
4
5
Line Fit
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
x
1
2
3
4
5
6
Where does the data come from?
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
x
1
2
3
4
5
6
Where does the data come from?
Random Experiment
and
Random Variable
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
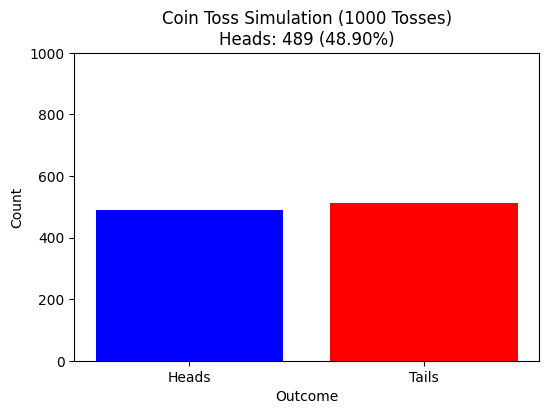
Heads, Tails, Tails, Heads, Heads ......
Guess the random Experiment that gives:
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
Heads, Tails, Tails, Heads, Heads ......
Guess the random Experiment that gives:
Flipping a coin - of course
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
Heads
x
Tails
\text{freq.}(x)
What can we expect about the outcome?
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
x
y
\( \text{class 0}\)
\( \text{class 1}\)
1
2
3
4
5
6
1
2
3
4
5
Decision Boundary
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
x
1
2
3
5
6
4
Where does the data come from?
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
x
1
2
3
5
6
4
Interpolation for data generation
Can I interpolate between data points?
x_{\text{new}} = (1 - \lambda) x_1 + \lambda x_2,\quad \lambda \in [0, 1]
Basic idea behind morphing images, style mixing, data augmentation
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
x
1
2
3
5
6
4
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
x
1
2
3
5
6
4
\text{freq.}(x)
What is the Data Distribution?
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
What is a Probability Distribution?
A probability distribution describes how the probability mass (discrete) or probability density (continuous) is assigned to different possible outcomes of a random variable.
For a discrete variable X:
P(X = x) \quad \text{gives the probability that } X \text{ takes the value } x.
For a continuous variable X with PDF \( p(x) \):
P(a \leq X \leq b) = \int_a^b p(x)\,dx
\quad \text{with} \quad p(x) \geq 0,
\quad \int_{-\infty}^{\infty} p(x) dx = 1.
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
What is a Probability Distribution?
p_\theta(x) = \frac{e^{-f_\theta(x)}}{Z_\theta}
- \( p_\theta(x)\) : probability density or mass function parameterized by \( \theta \).
- \( f_\theta(x) \) : energy function or negative log probability
- \( Z_\theta \) : partition function (normalization constant) that ensures the total probability integrates or sums to 1.
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
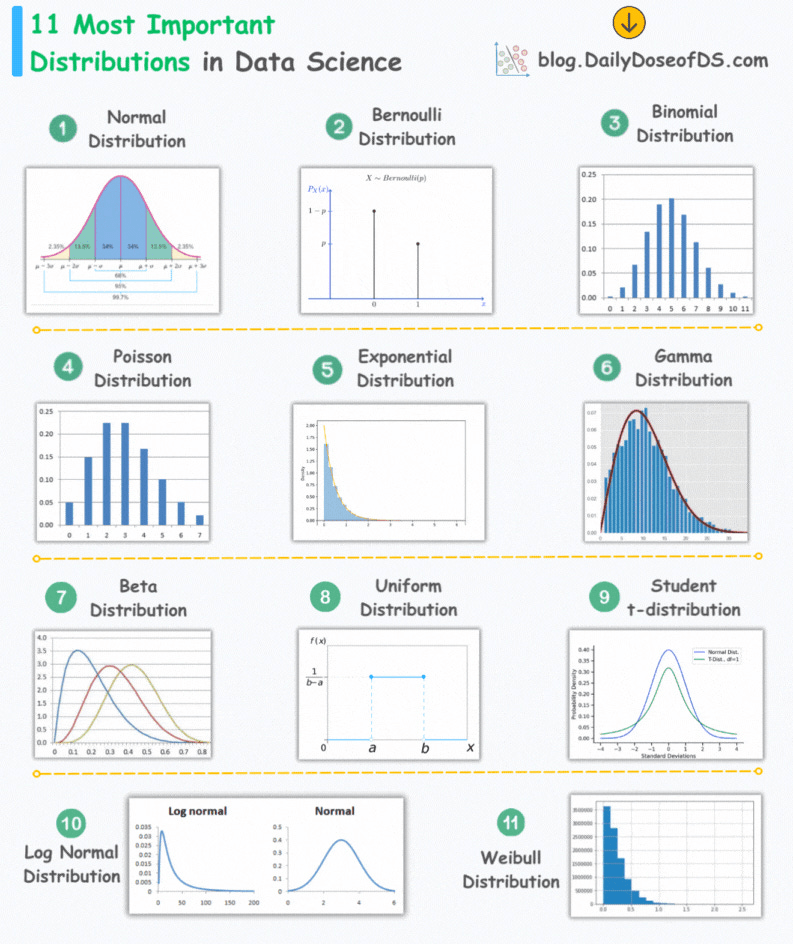
\text{Types of Distributions}
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
\text{Gaussian Distribution}
Mean - \( \mu \)
Variance - \( \sigma^2 \)
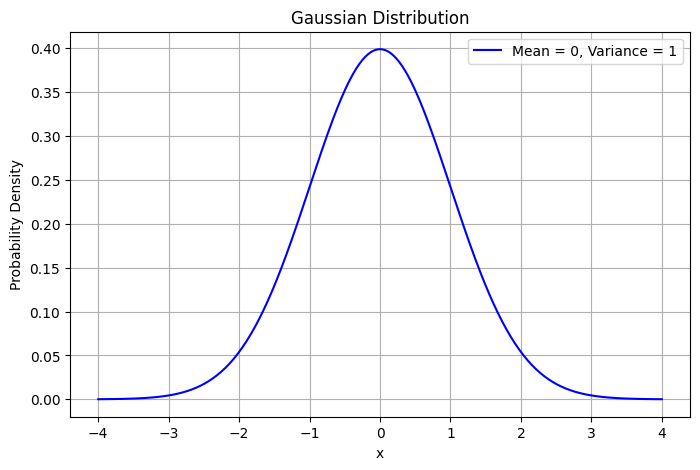
f(x) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{(x - \mu)^2}{2 \sigma^2}\right)
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
\text{Gaussian Distribution}
Variance - \( \sigma^2 \)
change
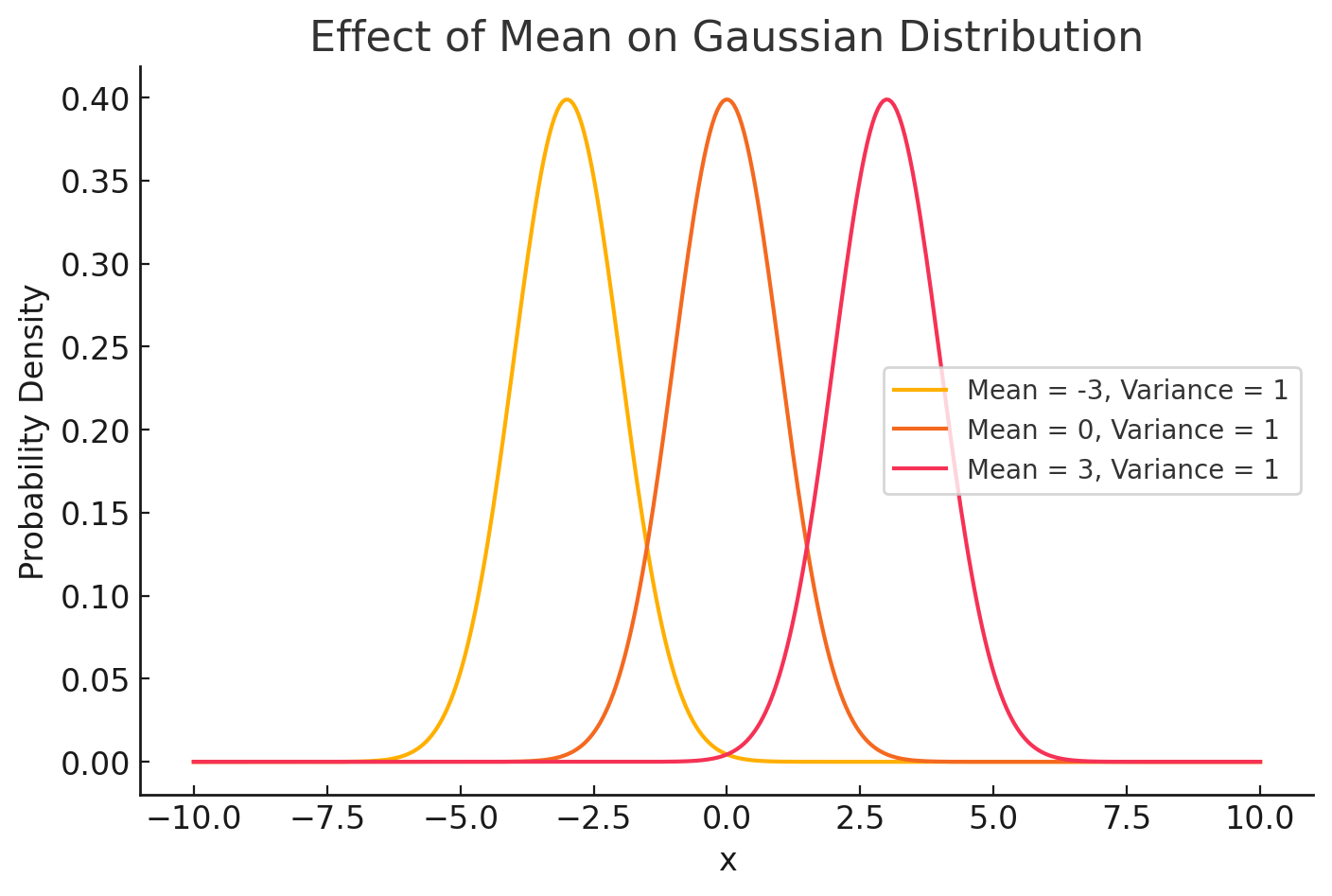
Mean - \( \mu \)
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
\text{Gaussian Distribution}
Mean - \( \mu \)
Variance - \( \sigma^2 \)
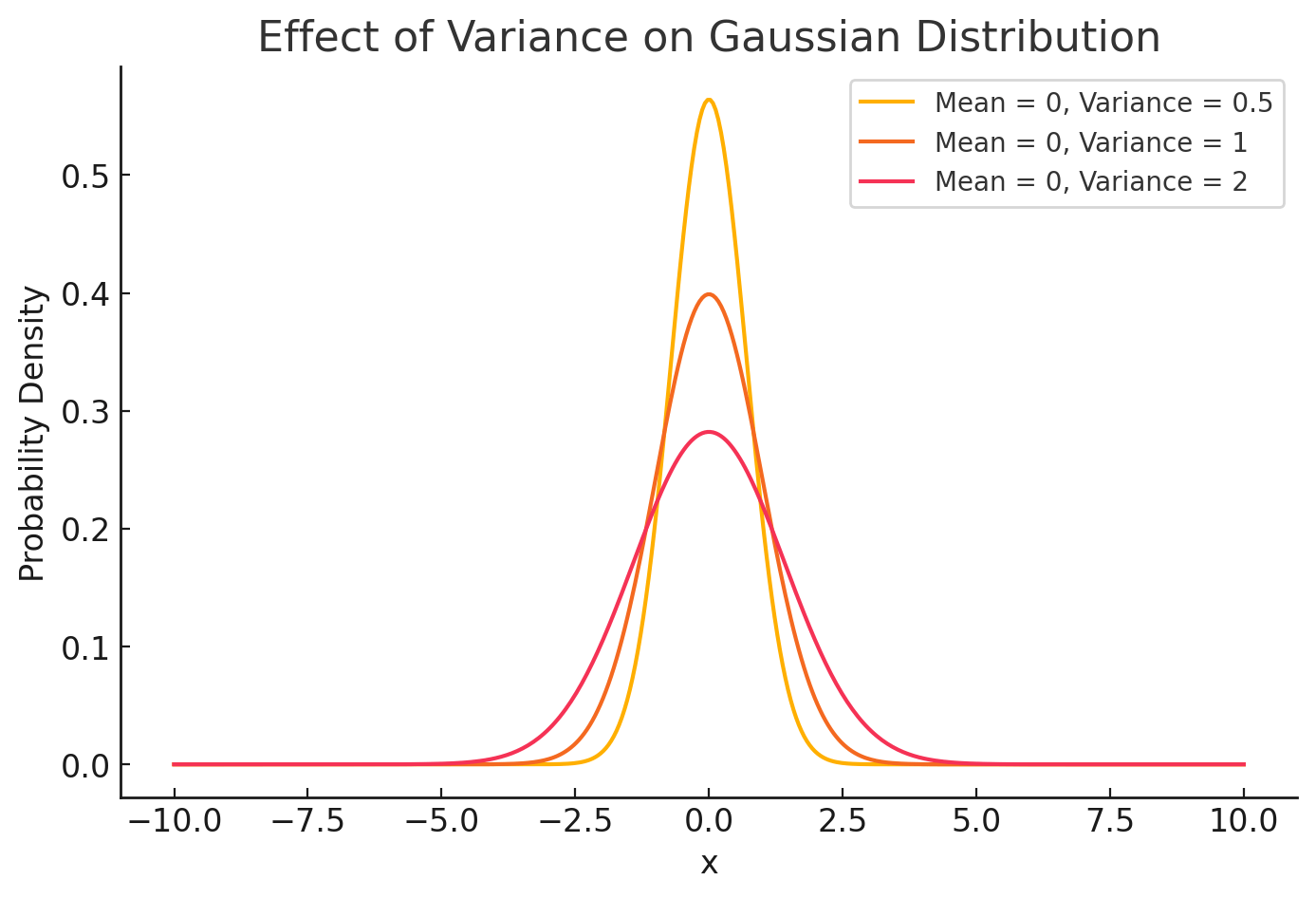
change
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
\text{Gaussian Distribution}
Mean - \( \mu \)
Variance - \( \sigma^2 \)
\mathcal{N}(x \mid \mu, \sigma^2)
\( x \) follows a normal distribution with mean \( \mu \) and variance \( \sigma^2 \)
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
\text{Useful notations}
Mean - \( \mu \)
Variance - \( \sigma^2 \)
x \sim \mathcal{N}(\mu, \sigma^2 I)
\mathcal{N}(x ; \mu, \sigma^2 I)
\mathcal{N}(x \mid \mu, \sigma^2 I)
All of these denote Gaussian distributions
A sample from the above distribution:
z = \mu + \sigma \cdot \varepsilon, \quad \text{where} \quad \varepsilon \sim \mathcal{N}(0,1)
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
\text{Useful properties of Gaussian Distribution}
Suppose \( x_1 \sim \mathcal{N}(\mu_1, \sigma_1^2 I) \) and \( x_2 \sim \mathcal{N}(\mu_2, \sigma_2^2 I) \).
What is the distribution of \( x_1 + x_2 \)?
x_1 + x_2 \sim \mathcal{N}(\mu_1 + \mu_2, (\sigma_1^2 + \sigma_2^2) I)
Suppose \( \boldsymbol{\varepsilon}_1, \boldsymbol{\varepsilon}_2 \sim \mathcal{N}(0, I) \), and
\( \boldsymbol{x}_1 = \sigma_1 \boldsymbol{\varepsilon}_1 \quad \text{and} \quad \boldsymbol{x}_2 = \sigma_2 \boldsymbol{\varepsilon}_2 \)
\( \boldsymbol{x}_1 + \boldsymbol{x}_2 \sim \mathcal{N}(0, (\sigma_1^2 + \sigma_2^2)I) \).
\( \boldsymbol{x}_1 + \boldsymbol{x}_2 = \sqrt{\sigma_1^2 + \sigma_2^2} \, \boldsymbol{\varepsilon} \)
sample
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
\text{Useful properties of Gaussian Distribution}
\mathcal{N}(\mu_1, \sigma_1^2) \cdot \mathcal{N}(\mu_2, \sigma_2^2) \propto \mathcal{N}(\mu', \sigma'^2)
\mu' = \frac{\sigma_1^2 \mu_2 + \sigma_2^2 \mu_1}{\sigma_1^2 + \sigma_2^2}, \quad \sigma'^2 = \frac{\sigma_1^2 \sigma_2^2}{\sigma_1^2 + \sigma_2^2}
Product of two Gaussians is a Gaussian
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
Multivariate Probability Distribution
A multivariate distribution models the joint behavior of multiple random variables simultaneously. For example, a Multivariate Gaussian models the probability of a vector \( \mathbf{x} = [x_1, x_2, …, x_n] \).
General Form:
\( p(\mathbf{x}) = p(x_1, x_2, \ldots, x_n) \)
Joint probability tells us the likelihood of all variables taking specific values together.
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
Multivariate Gaussian
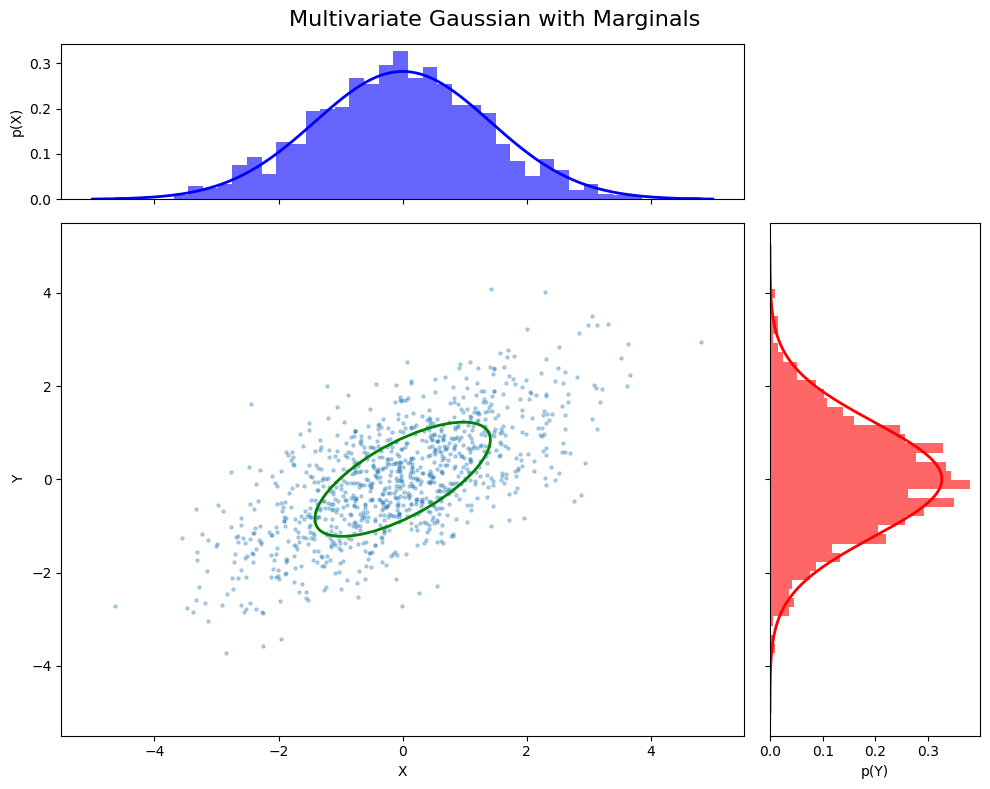
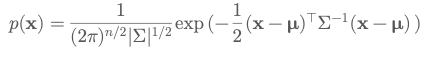
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
Conditional Probability:
Conditional probability quantifies the probability of an event given that another event has occurred.
p(x | y) = \frac{p(x, y)}{p(y)}
\quad \text{(if } p(y) > 0)
Reads as: “The probability of x given y”.
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
Marginalization:
Marginalization is the process of finding the distribution of a subset of variables by summing or integrating out others.
p(x) = \int p(x, y) \, dy
\quad \text{or} \quad
p(x) = \sum_{y} p(x, y)
Given \( p(x, y)\), the marginal of \(x\) is:
Interpretation: What is the probability of \( x \), regardless of \(y\)?
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
Bayes Rule:
Bayes’ Theorem relates conditional probabilities in both directions
p(x | y) = \frac{p(y | x) \, p(x)}{p(y)}
Prior
Evidence
Likelihood
Posterior
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
Expected Value:
The expected value (mean) of a random variable is its long-run average outcome
\mathbb{E}[X] = \int x \, p(x) \, dx
\quad \text{or} \quad
\mathbb{E}[X] = \sum_x x \, p(x)
Represents the “center” of a distribution.
Useful for predictions, variance calculation, and loss expectations.
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
But, what about images?
Where does your sample come from?


\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
But, what about images?
\text{Generative Models}
Where does your sample come from?

\text{Data Distribution}
unknown
\text{Generative Models}
Where does your sample come from?
\text{Data Distribution}
unknown
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
But, what about images?
Images are multidimensional vectors
but, what does it mean when two images are closer to each other?
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
but, what does it mean when two images are closer to each other?
\text{Naresh Kumar Devulapally}
\text{CSE 4/573: CVIP, Summer 2025}
\text{July 10, 2025}
\text{Intro to GenAI: Data Distribution}
but, what does it mean when two images are closer to each other?
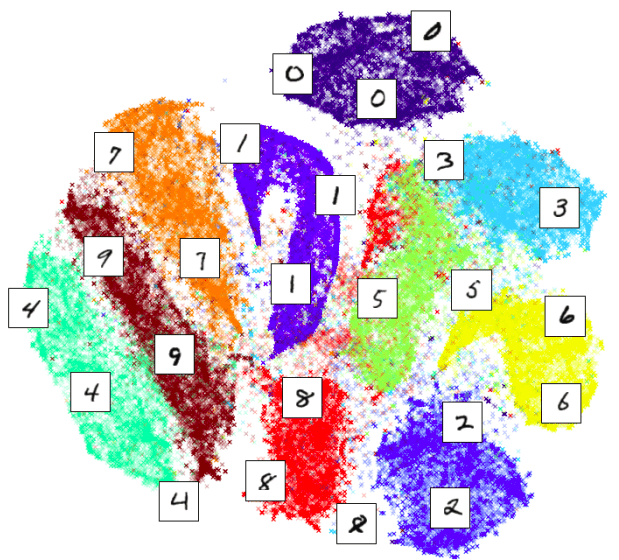
Closer in Low-Dimensional Feature Space
Lecture 12: Intro to GenAI: Data Distribution
By Naresh Kumar Devulapally



